
Monitoreo de E/S de disco con iostat y dstat
Introducción
Monitorear la entrada-salida del disco es una de las tareas clave al operar servidores en una infraestructura de hosting. El subsistema de disco afecta directamente el rendimiento de los servicios web, bases de datos, máquinas virtuales, contenedores y tareas en segundo plano. Incluso con suficiente RAM y recursos de CPU libres, un disco sobrecargado o lento puede convertirse en el cuello de botella de todo el sistema.
Este manual está destinado a administradores de sistemas, ingenieros DevOps y propietarios de servidores. Cubre las utilidades iostat y dstat, los principios de su operación, la interpretación de métricas y un enfoque práctico para encontrar cuellos de botella de E/S de disco en un entorno de hosting.
Información general y principios de operación
E/S de disco en una infraestructura de servidor
La entrada-salida de disco incluye operaciones de lectura y escritura de datos en dispositivos de bloque. En escenarios de hosting del mundo real, la carga en el subsistema de disco es generada más a menudo por:
- bases de datos (MySQL, MariaDB, PostgreSQL);
- aplicaciones web con contenido dinámico;
- servicios de correo;
- respaldo y sincronización de datos;
- registro de logs;
- archivos de intercambio y temporales;
- scripts de usuario y trabajos cron.
Los cuellos de botella pueden ocurrir debido a dispositivos de almacenamiento lentos, alta contención entre procesos, planificadores de E/S no óptimos, operación incorrecta de caché o características de virtualización.
Propósito de iostat y dstat
iostat es una utilidad del paquete sysstat diseñada para recopilar estadísticas detalladas sobre la carga de CPU y dispositivos de disco. La tarea principal de iostat es mostrar cuán intensivamente se está utilizando un disco específico, si hay una cola de solicitudes y cuál es el tiempo de espera promedio para las operaciones.
dstat es una herramienta de monitoreo versátil que muestra estadísticas en tiempo real a través de varios subsistemas a la vez: CPU, memoria, disco, red, procesos. Permite correlacionar la actividad del disco con la carga general del servidor y es conveniente para diagnósticos rápidos.
Estas utilidades se complementan entre sí: iostat proporciona una imagen precisa a nivel de dispositivo, mientras que dstat proporciona el contexto de todo el sistema.
Requisitos previos y requisitos
Antes de comenzar el análisis, se deben cumplir las siguientes condiciones:
- Sistema operativo Linux (Debian, Ubuntu, AlmaLinux, Rocky Linux, CentOS).
- Acceso SSH al servidor.
- Privilegios de root o la capacidad de ejecutar comandos a través de sudo.
Verificación de la versión del SO:
cat /etc/os-release
Instalación de los paquetes necesarios.
Debian / Ubuntu:
sudo apt update
sudo apt install sysstat dstat
CentOS / RHEL / AlmaLinux / Rocky Linux:
sudo yum install sysstat dstat
sudo dnf install sysstat dstat
Verificación del funcionamiento de sysstat:
systemctl status sysstat
Si el servicio está activo, se mostrará la información relevante:
root@server:~# systemctl status sysstat ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; preset: enabled) Active: active (exited) since Tue 2025-12-23 10:35:35 UTC; 16min ago Docs: man:sa1(8) man:sadc(8) man:sar(1) Main PID: 731 (code=exited, status=0/SUCCESS) CPU: 7ms
Revisión y análisis paso a paso
Análisis básico del disco usando iostat
La utilidad iostat se utiliza para evaluar la carga del subsistema de CPU y disco, así como para identificar retrasos y colas de E/S.
Sintaxis:
sudo iostat [options] [interval] [count]
Parámetros más comúnmente usados:
- -x — estadísticas extendidas;
- -d — datos solo de disco;
- -k — salida en kilobytes;
- -p — estadísticas para particiones o un dispositivo específico.
Ejemplo básico:
sudo iostat -x
Análisis dinámico:
sudo iostat -xk 5 3
El intervalo y el número de muestras permiten rastrear cambios de carga a lo largo del tiempo, en lugar del estado promedio desde el arranque del sistema.
Ejemplo de salida de iostat:
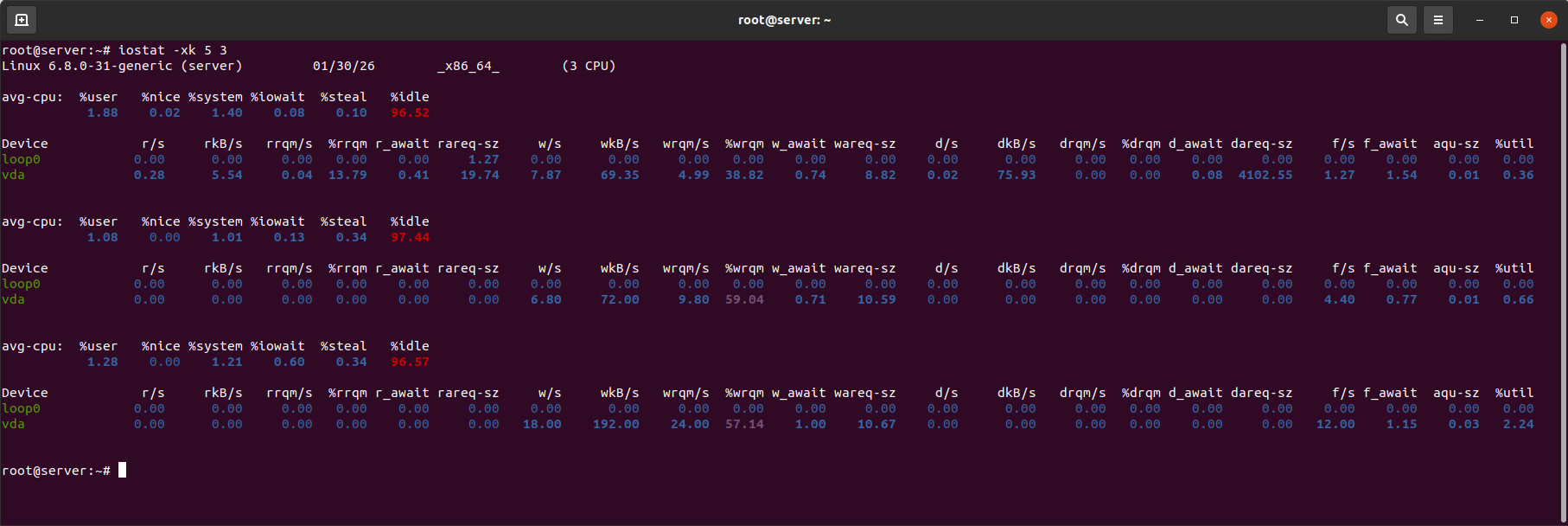
Métricas clave de CPU:
- %iowait — el porcentaje de tiempo que la CPU está inactiva mientras espera operaciones de E/S. Un aumento en esta métrica indica el impacto del disco en el rendimiento general.
- %steal — relevante para servidores virtuales y muestra el tiempo de CPU robado.
Métricas clave de disco:
- %util — el porcentaje de tiempo que el disco estuvo ocupado. Valores que consistentemente superan el 80–90% indican saturación del dispositivo.
- r_await — el tiempo promedio (ms) para completar operaciones de lectura (incluyendo tiempo en cola).
- w_await — el tiempo promedio (ms) para completar operaciones de escritura (incluyendo tiempo en cola).
- aqu-sz — (tamaño promedio de cola) la longitud promedio de la cola de solicitudes para el disco. Un valor > 1 ya indica la formación de una cola. Un valor > 2–4 para HDD / > 1–2 para SSD es una señal de que el disco no está manteniendo el ritmo con la carga.
La diferencia entre await y svctm muestra si el retraso es causado por la cola, en lugar de la velocidad física del disco.
Si await solo excede ligeramente a svctm (diferencia < 20–30%), los retrasos son causados principalmente por el propio disco (lectura/escritura física lenta).
Si await es significativamente mayor que svctm (diferencia > 50–100%), el principal retraso es causado por la cola de solicitudes (aqu-sz será alta), indicando sobrecarga del disco por muchas solicitudes paralelas.
En versiones modernas de iostat (como en el ejemplo), svctm no se muestra porque su cálculo no es confiable. Para el análisis, se utiliza la combinación de await + aqu-sz: await alto con aqu-sz bajo (~0) indica un disco lento; await alto con aqu-sz alto (>1) indica que el disco está sobrecargado con solicitudes.
Análisis de la imagen general con dstat
dstat se utiliza para la observación del sistema en tiempo real y para correlacionar la carga del disco con otros recursos.
Ejemplos de comandos:
dstat -d
dstat --disk-util
dstat -rd --disk-util
dstat -D vda,sda
Ejemplo de ejecución con un intervalo:
dstat -rd --disk-util 1 5
Al analizar, preste atención a:
- aumento en iowait en CPU;
- picos de lectura o escritura;
- actividad simultánea de red y disco (respaldos, sincronización).
Ejemplo de salida de dstat:
dstat -rd --disk-util 1 5 --io/total- -dsk/total- vda- read write| read write|util 0 4.00 | 0 76k|0.50 0 29.5 | 0 240k|0.20 0 1.00 | 0 4096B| 0 0 0 | 0 0 | 0 0 1.00 | 0 32k| 0
Comparación de dstat e iostat:
| Criterios | iostat | dstat |
|---|---|---|
| Precisión de datos | Alta | Alta |
| Modo en tiempo real | Limitado | Excelente |
| Datos históricos | Sí (sar) | No |
| Salida en color | No | Sí |
| Extensibilidad | No | Plugins |
| Exportación CSV | No | Sí |
| Carga de CPU | Baja | Media |
dstat es particularmente útil para picos de carga a corto plazo que no siempre son visibles en iostat.
Identificación de cuellos de botella de E/S de disco
Los siguientes comandos se utilizan para diagnósticos rápidos:
sudo iostat -mx 2
sudo iostat -p /dev/vda 2 5
sar -d 1 5
Signos típicos de un problema:
- %util por encima del 80% durante un período prolongado;
- await por encima de 20–30 ms para SSD o por encima de 50–100 ms para HDD;
- aqu-sz mayor que 2–3, indicando acumulación de cola.
En el ejemplo, se utiliza el disco /dev/vda — este es un disco virtual (VirtIO) en un servidor virtual. En servidores físicos y en otros entornos, los discos pueden tener nombres diferentes.
- /dev/sdX (por ejemplo, /dev/sda) — discos SATA/SAS/USB regulares
- /dev/nvmeXnY (por ejemplo, /dev/nvme0n1) — unidades NVMe
- /dev/vdX — discos virtuales
Identificación de procesos que causan alta carga de E/S de disco
Después de establecer la presencia de sobrecarga del subsistema de disco usando iostat y dstat, el siguiente paso es identificar los procesos específicos que inician operaciones intensivas de lectura o escritura. El análisis a nivel de dispositivo sin identificar la fuente de carga no permite tomar acciones correctivas adecuadas.
Usando iotop
La herramienta principal para encontrar procesos que están utilizando activamente el disco es la utilidad iotop.
sudo iotop -ao
Parámetros del comando:
- -a — muestra estadísticas acumulativas desde que el proceso comenzó, lo que ayuda a identificar tareas en segundo plano con E/S a largo plazo;
- -o — muestra solo aquellos procesos que actualmente están realizando operaciones de E/S.
Ejemplo de salida:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 11056 be/4 mysql 0.00 B 3.44 M 0.00 % 0.76 % mysqld 2580 be/4 rsync 0.00 B 23.48 M 0.00 % 1.17 % rsync
En la salida de iotop, se debe prestar especial atención a los campos DISK READ, DISK WRITE y al porcentaje de tiempo de I/O. Típicamente, las fuentes de carga son procesos de bases de datos, procesos de respaldo, procesos de sincronización de archivos o scripts de usuario.
Usando pidstat para análisis de E/S por proceso
Para un análisis más formalizado y repetible, se puede usar pidstat, que es parte del paquete sysstat.
pidstat -d 1
Este comando muestra estadísticas de E/S de disco para cada proceso en intervalos de un segundo. Esto es conveniente para identificar picos de actividad a corto plazo y correlacionarlos con otras métricas del sistema.
pidstat es particularmente útil en situaciones donde la carga aparece periódicamente y puede no siempre ser capturada por iotop.
Usando lsof para análisis de actividad de archivos
En casos donde es necesario entender con qué archivos o directorios específicos está trabajando un proceso, se utiliza la utilidad lsof.
lsof +D /path
Dónde /path es un directorio específico dentro del cual se necesitan identificar archivos y procesos activos. Por ejemplo, este podría ser un directorio de base de datos, un directorio de respaldo o un área de archivos temporales.
El comando permite determinar qué procesos están actualmente manteniendo descriptores de archivos y realizando operaciones dentro de la ruta especificada, lo cual es especialmente útil al analizar la carga de aplicaciones.
Análisis del contexto de carga
Identificar un proceso con alta actividad de disco no es el objetivo final. El administrador necesita evaluar el contexto de su operación:
- ¿es la carga esperada para este servicio?
- ¿el proceso se está ejecutando en un momento apropiado (por ejemplo, respaldos durante horas pico)?
- ¿se puede cambiar el horario o los parámetros operativos?
- ¿es permisible reducir la prioridad de E/S?
Este enfoque permite distinguir la carga normal de la carga problemática y elegir el método de optimización correcto.
Verificación de la corrección del análisis
La corrección del análisis realizado se confirma si:
- los picos en %util, await o aqu-sz en iostat coinciden en el tiempo con la actividad del proceso en iotop o pidstat;
- un aumento en iowait en dstat coincide con operaciones de disco, y no con carga de CPU;
- mediciones repetidas muestran un patrón de carga reproducible.
Para la acumulación de datos y análisis posterior, se recomienda usar el registro:
sar -d 1 100 > io.log
Esto permite registrar el comportamiento del subsistema de disco durante un período especificado y usar los datos al investigar incidentes.
Errores típicos y características operativas
En la práctica de operar servidores de hosting, los siguientes problemas son los más comunes:
- ejecución de respaldos y sincronización de datos durante horas pico;
- uso intensivo de swap cuando hay insuficiente RAM;
- un planificador de E/S inadecuado para el tipo de unidad;
- falta de priorización para tareas en segundo plano.
Para reducir el impacto de los procesos en segundo plano en el rendimiento, se recomienda usar la utilidad ionice para gestionar la prioridad de E/S de un proceso, lo que permite disminuir el impacto de las tareas en segundo plano en la capacidad de respuesta del sistema.
Ejemplo de uso:
ionice -c3 rsync /source /destination
Prioridades clave:
- -c1 (tiempo real) — la prioridad más alta. Usado para tareas críticas de latencia. Puede bloquear completamente otros procesos.
- -c2 (mejor esfuerzo) — el valor predeterminado para la mayoría de los procesos. Permite el ajuste del nivel de prioridad (de 0 (alto) a 7 (bajo)).
- -c3 (inactivo) — en segundo plano. El proceso solo obtendrá acceso al disco cuando ningún otro proceso lo esté utilizando. Seguro y recomendado para operaciones en segundo plano (respaldos, sincronización de datos).
En este ejemplo, el proceso rsync se ejecuta con la prioridad de E/S más baja, minimizando su impacto en las operaciones principales del sistema. Usar ionice permite minimizar el impacto de los procesos en segundo plano sin necesidad de desactivarlos completamente.
Conclusión
Monitorear la E/S de disco es una parte integral del mantenimiento del rendimiento y la estabilidad de una infraestructura de servidor. Las utilidades iostat y dstat permiten identificar situaciones de sobrecarga y evaluar el estado del subsistema de disco, mientras que herramientas como iotop, pidstat y lsof ayudan a identificar procesos específicos y la naturaleza de su carga.
La aplicación regular del enfoque descrito, la correcta interpretación de métricas y la gestión de prioridades de E/S ayudan a reducir los tiempos de respuesta del servicio, aumentar la previsibilidad de la carga y asegurar el cumplimiento de los requisitos de SLA. Posteriormente, esta metodología puede expandirse a través de monitoreo centralizado y automatización del análisis de carga de E/S.




















































