
Monitoraggio dell'I/O del disco con iostat e dstat
Introduzione
Monitorare l'input-output del disco è uno dei compiti chiave quando si gestiscono server in un'infrastruttura di hosting. Il sottosistema del disco influisce direttamente sulle prestazioni dei servizi web, database, macchine virtuali, container e attività in background. Anche con RAM sufficiente e risorse CPU libere, un disco sovraccarico o lento può diventare il collo di bottiglia dell'intero sistema.
Questo manuale è destinato agli amministratori di sistema, ingegneri DevOps e proprietari di server. Copre le utility iostat e dstat, i principi del loro funzionamento, l'interpretazione delle metriche e un approccio pratico per individuare i colli di bottiglia dell'I/O del disco in un ambiente di hosting.
Informazioni generali e principi operativi
I/O del disco in un'infrastruttura server
L'input-output del disco include operazioni di lettura e scrittura di dati su dispositivi a blocchi. In scenari di hosting reali, il carico sul sottosistema del disco è più spesso generato da:
- database (MySQL, MariaDB, PostgreSQL);
- applicazioni web con contenuti dinamici;
- servizi di posta;
- backup e sincronizzazione dei dati;
- logging;
- swap e file temporanei;
- script utente e cron job.
I colli di bottiglia possono verificarsi a causa di dispositivi di archiviazione lenti, alta contesa tra processi, scheduler I/O non ottimali, funzionamento errato della cache o caratteristiche di virtualizzazione.
Scopo di iostat e dstat
iostat è un'utilità del pacchetto sysstat progettata per raccogliere statistiche dettagliate sul carico della CPU e dei dispositivi disco. Il compito principale di iostat è mostrare quanto intensamente viene utilizzato un disco specifico, se c'è una coda di richieste e qual è il tempo medio di attesa per le operazioni.
dstat è uno strumento di monitoraggio versatile che visualizza statistiche in tempo reale su diversi sottosistemi contemporaneamente: CPU, memoria, disco, rete, processi. Permette di correlare l'attività del disco con il carico complessivo del server ed è comodo per diagnosi rapide.
Queste utility si completano a vicenda: iostat fornisce un quadro accurato a livello di dispositivo, mentre dstat fornisce il contesto dell'intero sistema.
Prerequisiti e requisiti
Prima di iniziare l'analisi, devono essere soddisfatte le seguenti condizioni:
- Sistema operativo Linux (Debian, Ubuntu, AlmaLinux, Rocky Linux, CentOS).
- Accesso SSH al server.
- Privilegi di root o la possibilità di eseguire comandi tramite sudo.
Verifica della versione del sistema operativo:
cat /etc/os-release
Installazione dei pacchetti necessari.
Debian / Ubuntu:
sudo apt update
sudo apt install sysstat dstat
CentOS / RHEL / AlmaLinux / Rocky Linux:
sudo yum install sysstat dstat
sudo dnf install sysstat dstat
Verifica del funzionamento di sysstat:
systemctl status sysstat
Se il servizio è attivo, verranno visualizzate le informazioni pertinenti:
root@server:~# systemctl status sysstat ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; preset: enabled) Active: active (exited) since Tue 2025-12-23 10:35:35 UTC; 16min ago Docs: man:sa1(8) man:sadc(8) man:sar(1) Main PID: 731 (code=exited, status=0/SUCCESS) CPU: 7ms
Revisione e analisi passo-passo
Analisi di base del disco usando iostat
L'utilità iostat viene utilizzata per valutare il carico della CPU e del sottosistema del disco, nonché per identificare ritardi e code I/O.
Sintassi:
sudo iostat [options] [interval] [count]
Parametri più comunemente usati:
- -x — statistiche estese;
- -d — dati solo del disco;
- -k — output in kilobyte;
- -p — statistiche per partizioni o un dispositivo specifico.
Esempio di base:
sudo iostat -x
Analisi dinamica:
sudo iostat -xk 5 3
L'intervallo e il numero di campioni consentono di monitorare i cambiamenti di carico nel tempo, piuttosto che lo stato medio dall'avvio del sistema.
Esempio di output di iostat:
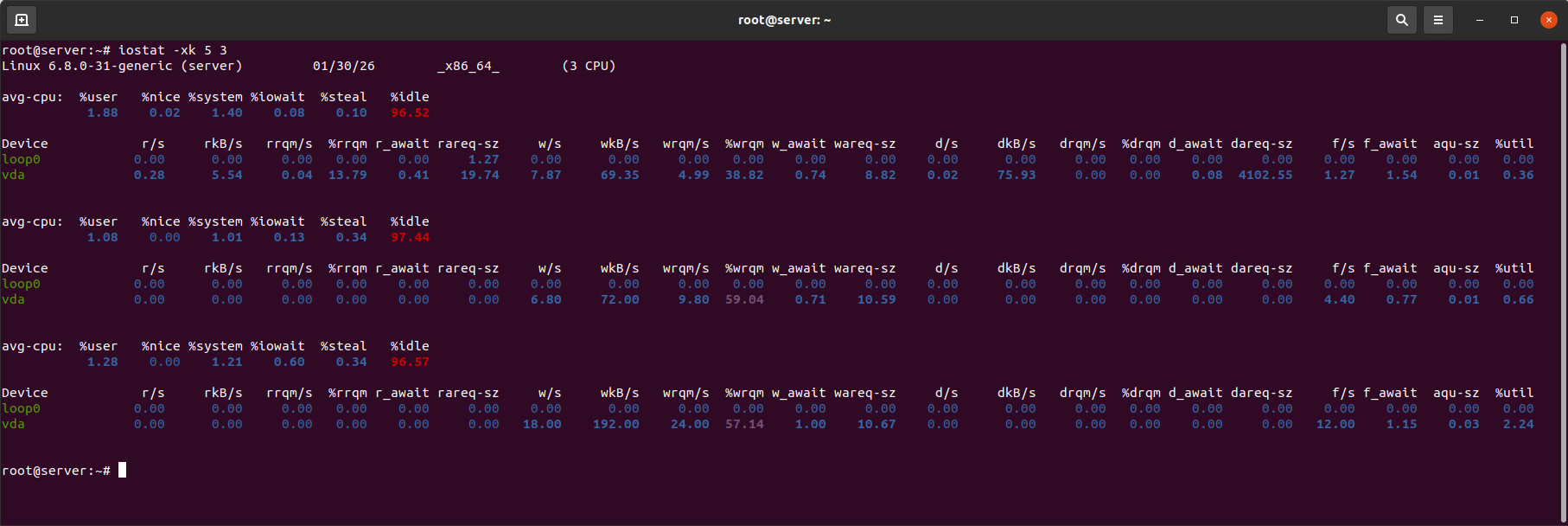
Metriche chiave della CPU:
- %iowait — la percentuale di tempo in cui la CPU è inattiva in attesa di operazioni I/O. Un aumento di questa metrica indica l'impatto del disco sulle prestazioni complessive.
- %steal — rilevante per i server virtuali e mostra il tempo CPU rubato.
Metriche chiave del disco:
- %util — la percentuale di tempo in cui il disco è stato occupato. Valori costantemente superiori all'80–90% indicano saturazione del dispositivo.
- r_await — il tempo medio (ms) per completare le operazioni di lettura (incluso il tempo di coda).
- w_await — il tempo medio (ms) per completare le operazioni di scrittura (incluso il tempo di coda).
- aqu-sz — (dimensione media della coda) la lunghezza media della coda di richieste per il disco. Un valore > 1 indica già la formazione di una coda. Un valore > 2–4 per HDD / > 1–2 per SSD è un segno che il disco non sta tenendo il passo con il carico.
La differenza tra await e svctm mostra se il ritardo è causato dalla coda, piuttosto che dalla velocità fisica del disco.
Se await supera solo leggermente svctm (differenza < 20–30%), i ritardi sono principalmente causati dal disco stesso (lettura/scrittura fisica lenta).
Se await è significativamente maggiore di svctm (differenza > 50–100%), il ritardo principale è causato dalla coda di richieste (aqu-sz sarà alto), indicando un sovraccarico del disco da molte richieste parallele.
Nelle versioni moderne di iostat (come nell'esempio), svctm non viene visualizzato perché il suo calcolo è inaffidabile. Per l'analisi, si utilizza la combinazione di await + aqu-sz: un alto await con un basso aqu-sz (~0) indica un disco lento; un alto await con un alto aqu-sz (>1) indica che il disco è sovraccarico di richieste.
Analisi del quadro generale con dstat
dstat viene utilizzato per l'osservazione del sistema in tempo reale e per correlare il carico del disco con altre risorse.
Esempi di comando:
dstat -d
dstat --disk-util
dstat -rd --disk-util
dstat -D vda,sda
Esempio di esecuzione con un intervallo:
dstat -rd --disk-util 1 5
Durante l'analisi, prestare attenzione a:
- aumento di iowait nella CPU;
- picchi di lettura o scrittura;
- attività simultanea di rete e disco (backup, sincronizzazione).
Esempio di output di dstat:
dstat -rd --disk-util 1 5 --io/total- -dsk/total- vda- read write| read write|util 0 4.00 | 0 76k|0.50 0 29.5 | 0 240k|0.20 0 1.00 | 0 4096B| 0 0 0 | 0 0 | 0 0 1.00 | 0 32k| 0
Confronto tra dstat e iostat:
| Criteri | iostat | dstat |
|---|---|---|
| Accuratezza dei dati | Alta | Alta |
| Modalità in tempo reale | Limitata | Eccellente |
| Dati storici | Sì (sar) | No |
| Output colorato | No | Sì |
| Estensibilità | No | Plugin |
| Esportazione CSV | No | Sì |
| Carico CPU | Basso | Medio |
dstat è particolarmente utile per picchi di carico a breve termine che non sono sempre visibili in iostat.
Identificazione dei colli di bottiglia dell'I/O del disco
I seguenti comandi vengono utilizzati per una diagnosi rapida:
sudo iostat -mx 2
sudo iostat -p /dev/vda 2 5
sar -d 1 5
Segni tipici di un problema:
- %util sopra l'80% per un periodo prolungato;
- await sopra i 20–30 ms per SSD o sopra i 50–100 ms per HDD;
- aqu-sz maggiore di 2–3, indicando la formazione di una coda.
Nell'esempio, viene utilizzato il disco /dev/vda — questo è un disco virtuale (VirtIO) su un server virtuale. Su server fisici e in altri ambienti, i dischi possono essere denominati diversamente.
- /dev/sdX (es. /dev/sda) — dischi SATA/SAS/USB regolari
- /dev/nvmeXnY (es. /dev/nvme0n1) — unità NVMe
- /dev/vdX — dischi virtuali
Identificazione dei processi che causano un alto carico I/O del disco
Dopo aver stabilito la presenza di un sovraccarico del sottosistema del disco utilizzando iostat e dstat, il passo successivo è identificare i processi specifici che avviano operazioni di lettura o scrittura intensive. L'analisi a livello di dispositivo senza identificare la fonte del carico non consente di intraprendere azioni correttive corrette.
Utilizzo di iotop
Lo strumento principale per trovare i processi che stanno utilizzando attivamente il disco è l'utilità iotop.
sudo iotop -ao
Parametri del comando:
- -a — visualizza statistiche cumulative dall'avvio del processo, il che aiuta a identificare attività in background con I/O a lungo termine;
- -o — mostra solo quei processi che stanno attualmente eseguendo operazioni I/O.
Esempio di output:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 11056 be/4 mysql 0.00 B 3.44 M 0.00 % 0.76 % mysqld 2580 be/4 rsync 0.00 B 23.48 M 0.00 % 1.17 % rsync
Nell'output di iotop, particolare attenzione dovrebbe essere prestata ai campi DISK READ, DISK WRITE e alla percentuale di tempo I/O. Tipicamente, le fonti di carico sono processi di database, processi di backup, processi di sincronizzazione file o script utente.
Utilizzo di pidstat per l'analisi I/O per processo
Per un'analisi più formalizzata e ripetibile, può essere utilizzato pidstat, che fa parte del pacchetto sysstat.
pidstat -d 1
Questo comando fornisce statistiche I/O del disco per ciascun processo a intervalli di un secondo. Questo è conveniente per identificare picchi di attività a breve termine e correlare con altre metriche di sistema.
pidstat è particolarmente utile in situazioni in cui il carico appare periodicamente e potrebbe non essere sempre catturato da iotop.
Utilizzo di lsof per l'analisi dell'attività dei file
Nei casi in cui è necessario capire con quali file o directory specifici un processo sta lavorando, viene utilizzata l'utilità lsof.
lsof +D /path
Dove /path è una directory specifica all'interno della quale è necessario identificare file e processi attivi. Ad esempio, potrebbe essere una directory di database, una directory di backup o un'area di file temporanei.
Il comando consente di determinare quali processi stanno attualmente tenendo descrittori di file ed eseguendo operazioni all'interno del percorso specificato, il che è particolarmente utile quando si analizza il carico da applicazioni.
Analisi del contesto del carico
Identificare un processo con alta attività del disco non è l'obiettivo finale. L'amministratore deve valutare il contesto del suo funzionamento:
- il carico è previsto per questo servizio;
- il processo è in esecuzione in un momento appropriato (es. backup durante le ore di punta);
- è possibile modificare il programma o i parametri operativi;
- è consentito ridurre la priorità I/O.
Questo approccio consente di distinguere il carico normale da quello problematico e di scegliere il metodo di ottimizzazione corretto.
Verifica della correttezza dell'analisi
La correttezza dell'analisi eseguita è confermata se:
- i picchi in %util, await o aqu-sz in iostat coincidono nel tempo con l'attività del processo in iotop o pidstat;
- un aumento di iowait in dstat coincide con le operazioni del disco, e non con il carico della CPU;
- misurazioni ripetute mostrano un modello di carico riproducibile.
Per l'accumulo di dati e l'analisi successiva, si consiglia di utilizzare il logging:
sar -d 1 100 > io.log
Questo consente di registrare il comportamento del sottosistema del disco su un periodo specificato e utilizzare i dati durante l'indagine sugli incidenti.
Errori tipici e caratteristiche operative
Nella pratica di gestione dei server di hosting, i seguenti problemi sono più comuni:
- esecuzione di backup e sincronizzazione dei dati durante le ore di punta;
- uso intensivo dello swap quando la RAM è insufficiente;
- uno scheduler I/O non adatto al tipo di unità;
- mancanza di priorità per le attività in background.
Per ridurre l'impatto dei processi in background sulle prestazioni, si consiglia di utilizzare l'utilità ionice per gestire la priorità I/O di un processo, che consente di ridurre l'impatto delle attività in background sulla reattività del sistema.
Esempio di utilizzo:
ionice -c3 rsync /source /destination
Priorità chiave:
- -c1 (realtime) — la priorità più alta. Utilizzato per attività critiche per la latenza. Può bloccare completamente altri processi.
- -c2 (best-effort) — il default per la maggior parte dei processi. Consente la regolazione del livello di priorità (da 0 (alto) a 7 (basso)).
- -c3 (idle) — background. Il processo otterrà accesso al disco solo quando nessun altro processo lo sta utilizzando. Sicuro e raccomandato per operazioni in background (backup, sincronizzazione dati).
In questo esempio, il processo rsync viene eseguito con la priorità I/O più bassa, minimizzando il suo impatto sulle operazioni principali del sistema. L'uso di ionice consente di minimizzare l'impatto dei processi in background senza doverli disabilitare completamente.
Conclusione
Monitorare l'I/O del disco è parte integrante del mantenimento delle prestazioni e della stabilità di un'infrastruttura server. Le utility iostat e dstat consentono di identificare situazioni di sovraccarico e valutare lo stato del sottosistema del disco, mentre strumenti come iotop, pidstat e lsof aiutano a identificare processi specifici e la natura del loro carico.
L'applicazione regolare dell'approccio descritto, l'interpretazione corretta delle metriche e la gestione delle priorità I/O aiutano a ridurre i tempi di risposta del servizio, aumentare la prevedibilità del carico e garantire il rispetto dei requisiti SLA. Successivamente, questa metodologia può essere ampliata attraverso il monitoraggio centralizzato e l'automazione dell'analisi del carico I/O.




















































