
Моніторинг дискового вводу-виводу за допомогою iostat та dstat
Вступ
Моніторинг дискового вводу-виводу є однією з ключових задач при експлуатації серверів у хостинговій інфраструктурі. Дискова підсистема безпосередньо впливає на роботу веб-сервісів, баз даних, віртуальних машин, контейнерів і фонових задач. Навіть за наявності достатнього обсягу оперативної пам'яті та вільних процесорних ресурсів перевантажений або повільний диск може стати вузьким місцем усієї системи.
Даний мануал призначено для системних адміністраторів, DevOps-інженерів та власників серверів. У ньому розглядаються утиліти iostat та dstat, принципи їх роботи, інтерпретація показників та практичний підхід до пошуку вузьких місць дискового I/O в хостинговому середовищі.
Загальні відомості та принципи роботи
Дисковий I/O у серверній інфраструктурі
Дисковий ввід-вивід включає операції читання та запису даних на блокові пристрої. У реальних сценаріях хостингу навантаження на дискову підсистему найчастіше створюють:
- бази даних (MySQL, MariaDB, PostgreSQL);
- веб-застосунки з динамічним контентом;
- поштові сервіси;
- резервне копіювання та синхронізація даних;
- логування;
- swap та тимчасові файли;
- користувацькі скрипти та cron-завдання.
Вузькі місця можуть виникати через повільні носії, високу конкуренцію між процесами, неоптимальні планувальники I/O, некорректну роботу кешування або особливості віртуалізації.
Призначення iostat та dstat
iostat – утиліта з пакету sysstat, призначена для збору детальної статистики щодо завантаження CPU та дискових пристроїв. Основне завдання iostat – показати, наскільки активно використовується конкретний диск, чи є черга запитів і який середній час очікування операцій.
dstat – універсальний інструмент моніторингу, що відображає в реальному часі статистику одночасно по декількох підсистемах: CPU, пам'ять, диск, мережа, процеси. Він дозволяє співвіднести дискову активність із загальним навантаженням на сервер і зручний для оперативної діагностики.
Ці утиліти доповнюють одна одну: iostat дає точну картину на рівні пристроїв, а dstat – контекст усієї системи.
Передумови та вимоги
Перед початком аналізу мають бути виконані такі умови:
- Операційна система Linux (Debian, Ubuntu, AlmaLinux, Rocky Linux, CentOS).
- Доступ до сервера по SSH.
- Права root або можливість виконання команд через sudo.
Перевірка версії ОС:
cat /etc/os-release
Встановлення необхідних пакетів.
Debian / Ubuntu:
sudo apt update
sudo apt install sysstat dstat
CentOS / RHEL / AlmaLinux / Rocky Linux:
sudo yum install sysstat dstat
sudo dnf install sysstat dstat
Перевірка роботи sysstat:
systemctl status sysstat
Якщо служба активна, буде показано відповідну інформацію:
root@server:~# systemctl status sysstat ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; preset: enabled) Active: active (exited) since Tue 2025-12-23 10:35:35 UTC; 16min ago Docs: man:sa1(8) man:sadc(8) man:sar(1) Main PID: 731 (code=exited, status=0/SUCCESS) CPU: 7ms
Покроковий розгляд та аналіз
Базовий аналіз дисків за допомогою iostat
Утиліта iostat використовується для оцінки завантаження процесора та дискової підсистеми, а також для виявлення затримок і черг I/O.
Синтаксис:
sudo iostat [options] [interval] [count]
Найбільш вживані параметри:
- -x — розширена статистика;
- -d — дані лише по дисках;
- -k — виведення у кілобайтах;
- -p — статистика по розділах або конкретному пристрою.
Базовий приклад:
sudo iostat -x
Динамічний аналіз:
sudo iostat -xk 5 3
Інтервал та кількість вибірок дозволяють відстежувати зміну навантаження в часі, а не усереднений стан з моменту завантаження системи.
Приклад виводу iostat:
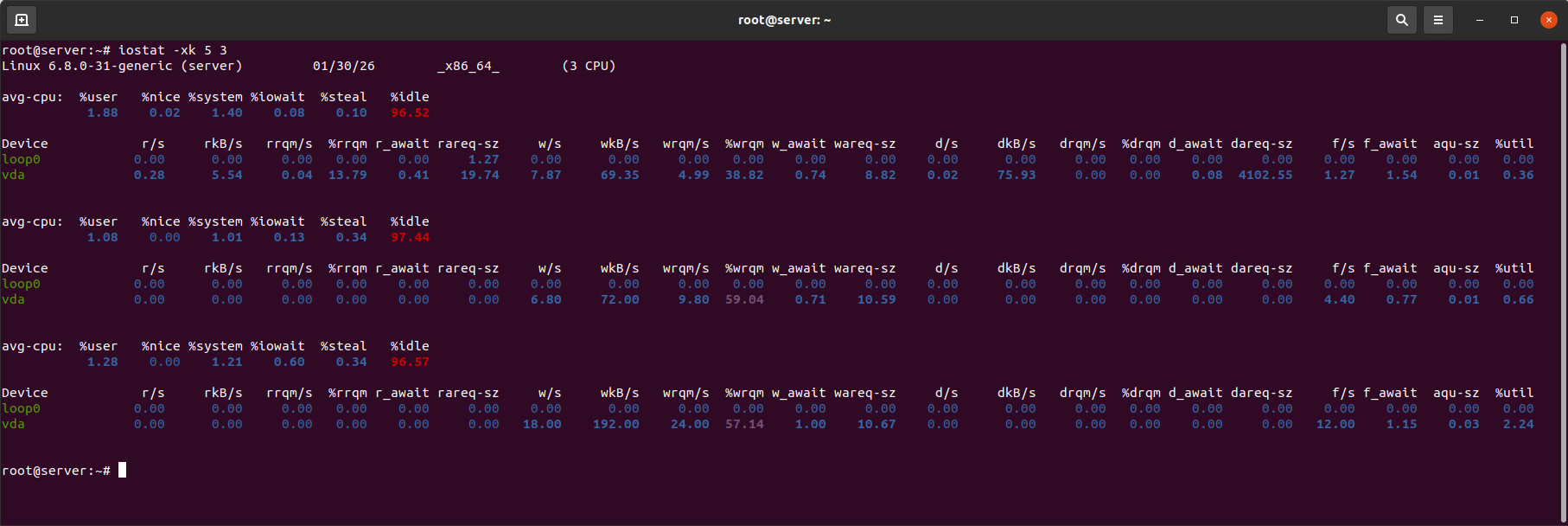
Ключові показники CPU:
- %iowait — частка часу, протягом якого CPU простоює в очікуванні операцій I/O. Зростання цього показника вказує на вплив диска на загальну продуктивність.
- %steal — актуальний для віртуальних серверів і показує втрачений час CPU.
Ключові показники диску:
- %util — відсоток часу, коли диск був зайнятий. Значення, що стабільно перевищують 80–90% вказують на насичення пристрою.
- r_await — середній час (мс) виконання операції читання (включаючи чергу).
- w_await — середній час (мс) виконання операції запису (включаючи чергу).
- aqu-sz — (avg queue size) середня довжина черги запитів до диска. Значення > 1 вже вказує на формування черги. Значення > 2–4 для HDD / > 1–2 для SSD — ознака того, що диск не справляється з навантаженням.
Різниця між await та svctm показує, чи створюється затримка чергою, а не фізичною швидкістю диску.
Якщо await лише незначно перевищує svctm (різниця < 20–30%), затримки в основному створюються самим диском (повільне фізичне читання/запис).
Якщо await значно більше svctm (різниця > 50–100%), основна затримка створюється чергою запитів (aqu-sz буде високим), це говорить про перевантаження диску множиною паралельних запитів.
У сучасних версіях iostat (як у прикладі) svctm не виводиться, оскільки його розрахунок ненадійний. Для аналізу використовується зв'язка await + aqu-sz: високий await при малому aqu-sz (~0) — повільний диск; високий await при високому aqu-sz (>1) — диск перевантажений запитами.
Аналіз загальної картини за допомогою dstat
dstat застосовується для спостереження за системою в реальному часі та кореляції дискового навантаження з іншими ресурсами.
Приклади команд:
dstat -d
dstat --disk-util
dstat -rd --disk-util
dstat -D vda,sda
Приклад запуску з інтервалом:
dstat -rd --disk-util 1 5
Під час аналізу слід звертати увагу на:
- зростання iowait у CPU;
- піки запису або читання;
- одночасну активність мережі та диска (резервні копії, синхронізація).
Приклад виводу dstat:
dstat -rd --disk-util 1 5 --io/total- -dsk/total- vda- read write| read write|util 0 4.00 | 0 76k|0.50 0 29.5 | 0 240k|0.20 0 1.00 | 0 4096B| 0 0 0 | 0 0 | 0 0 1.00 | 0 32k| 0
Порівняння dstat та iostat:
| Критерій | iostat | dstat |
|---|---|---|
| Точність даних | Висока | Висока |
| Режим реального часу | Обмежений | Відмінний |
| Історичні дані | Є (sar) | Немає |
| Кольоровий вивід | Немає | Є |
| Розширюваність | Немає | Плагіни |
| CSV експорт | Немає | Є |
| Завантаження CPU | Низька | Середня |
dstat особливо корисний при короткочасних сплесках навантаження, які не завжди помітні в iostat.
Виявлення вузьких місць дискового I/O
Для швидкої діагностики використовуються наступні команди:
sudo iostat -mx 2
sudo iostat -p /dev/vda 2 5
sar -d 1 5
Типові ознаки проблеми:
- %util вище 80% протягом тривалого часу;
- await вище 20–30 мс для SSD або вище 50–100 мс для HDD;
- aqu-sz більше 2–3, що вказує на накопичення черги.
У прикладі використовується диск /dev/vda — це віртуальний диск (VirtIO) на віртуальному сервері. На фізичних серверах та в інших середовищах диски можуть називатися інакше.
- /dev/sdX (наприклад, /dev/sda) — звичайні SATA/SAS/USB-диски
- /dev/nvmeXnY (наприклад, /dev/nvme0n1) — NVMe-накопичувачі
- /dev/vdX — віртуальні диски
Визначення процесів, що створюють високе навантаження на дисковий I/O
Після того, як за допомогою iostat та dstat встановлено наявність перевантаження дискової підсистеми, наступним кроком є визначення конкретних процесів, що ініціюють інтенсивні операції читання або запису. Аналіз на рівні пристроїв без виявлення джерела навантаження не дозволяє вжити коректних заходів.
Використання iotop
Основним інструментом для пошуку процесів, які активно використовують диск, є утиліта iotop.
sudo iotop -ao
Параметри команди:
- -a — відображення накопичувальної статистики з моменту запуску процесу, що дозволяє виявляти фонові завдання з тривалим I/O;
- -o — виведення тільки тих процесів, які в даний момент виконують операції введення-виведення.
Приклад виводу:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 11056 be/4 mysql 0.00 B 3.44 M 0.00 % 0.76 % mysqld 2580 be/4 rsync 0.00 B 23.48 M 0.00 % 1.17 % rsync
У виводі iotop особливу увагу слід звертати на поля DISK READ, DISK WRITE та відсоток часу I/O. Як правило, джерелами навантаження виступають процеси баз даних, резервного копіювання, синхронізації файлів або користувацькі скрипти.
Використання pidstat для аналізу I/O за процесами
Для більш формалізованого та повторюваного аналізу може застосовуватися pidstat, що входить до пакету sysstat.
pidstat -d 1
Дана команда виводить статистику дискового введення-виведення по кожному процесу з інтервалом в одну секунду. Це зручно для виявлення короткочасних сплесків активності та зіставлення їх з іншими метриками системи.
pidstat особливо корисний у ситуаціях, коли навантаження з'являється періодично і не завжди встигає бути зафіксованою iotop.
Використання lsof для аналізу файлової активності
У випадках, коли необхідно зрозуміти, з якими саме файлами або каталогами працює процес, застосовується утиліта lsof.
lsof +D /path
Де /path — це конкретний каталог, в межах якого потрібно визначити активні файли та процеси. Наприклад, це може бути каталог бази даних, директорія резервних копій або область тимчасових файлів.
Команда дозволяє встановити, які процеси в даний момент утримують файлові дескриптори та виконують операції у вказаному шляху, що особливо корисно при аналізі навантаження з боку застосунків.
Аналіз контексту навантаження
Виявлення процесу з високою дисковою активністю не є кінцевою метою. Адміністратору необхідно оцінити контекст його роботи:
- чи є навантаження очікуваним для даного сервісу;
- чи виконується процес у відповідний час (наприклад, резервне копіювання в години пік);
- чи можна змінити розклад або параметри роботи;
- чи допустиме зниження пріоритету введення-виведення.
Такий підхід дозволяє відрізнити штатне навантаження від проблемного та обрати коректний спосіб оптимізації.
Перевірка коректності аналізу
Коректність проведеного аналізу підтверджується у випадку, якщо:
- піки %util, await або aqu-sz в iostat збігаються за часом з активністю процесів в iotop або pidstat;
- зростання iowait в dstat збігається з дисковими операціями, а не з завантаженням CPU;
- повторні заміри показують відтворювану картину навантаження.
Для накопичення даних та подальшого аналізу рекомендується використовувати логування:
sar -d 1 100 > io.log
Це дозволяє зафіксувати поведінку дискової підсистеми протягом заданого періоду та використовувати дані при розборі інцидентів.
Типові помилки та особливості експлуатації
У практиці експлуатації серверів найчастіше зустрічаються наступні проблеми:
- виконання резервного копіювання та синхронізації даних у години пік;
- активне використання swap при нестачі оперативної пам'яті;
- невідповідний планувальник I/O для типу накопичувача;
- відсутність пріоритезації фонових завдань.
Для зниження впливу фонових процесів на продуктивність рекомендується використовувати утиліту ionice для керування пріоритетом операцій введення-виведення (I/O) процесу, яка дозволяє зменшити вплив фонових завдань на чуйність системи.
Приклад використання:
ionice -c3 rsync /source /destination
Ключові пріоритети:
- -c1 (realtime) — найвищий пріоритет. Використовується для критичних до затримок задач. Може повністю заблокувати інші процеси.
- -c2 (best-effort) — типовий для більшості процесів. Допускає уточнення пріоритету (від 0 (високий) до 7 (низький)).
- -c3 (idle) — фоновий. Процес отримає доступ до диска лише тоді, коли його не використовують інші. Безпечний і рекомендується для фонових операцій (резервне копіювання, синхронізація даних).
У даному прикладі процес rsync виконується з найнижчим пріоритетом I/O, мінімізуючи вплив на основну роботу системи. Використання ionice дозволяє мінімізувати вплив фонових процесів без необхідності їх повного відключення.
Висновок
Моніторинг дискового I/O є невід'ємною частиною підтримки продуктивності та стабільності серверної інфраструктури. Утиліти iostat та dstat дозволяють виявити факти перевантаження та оцінити стан дискової підсистеми, а інструменти iotop, pidstat та lsof — визначити конкретні процеси та характер їх навантаження.
Регулярне застосування описаного підходу, коректна інтерпретація метрик та керування пріоритетами введення-виведення дозволяють знизити час відгуку сервісів, підвищити передбачуваність навантаження та забезпечити виконання вимог SLA. У подальшому дана методика може бути розширена за рахунок централізованого моніторингу та автоматизації аналізу I/O-навантаження.




















































