
Monitoring Disk I/O with iostat and dstat
Introduction
Monitoring disk input-output is one of the key tasks when operating servers in a hosting infrastructure. The disk subsystem directly affects the performance of web services, databases, virtual machines, containers, and background tasks. Even with sufficient RAM and free CPU resources, an overloaded or slow disk can become the bottleneck of the entire system.
This manual is intended for system administrators, DevOps engineers, and server owners. It covers the iostat and dstat utilities, the principles of their operation, interpretation of metrics, and a practical approach to finding disk I/O bottlenecks in a hosting environment.
General information and operating principles
Disk I/O in a server infrastructure
Disk input-output includes read and write operations of data to block devices. In real-world hosting scenarios, the load on the disk subsystem is most often generated by:
- databases (MySQL, MariaDB, PostgreSQL);
- web applications with dynamic content;
- mail services;
- data backup and synchronization;
- logging;
- swap and temporary files;
- user scripts and cron jobs.
Bottlenecks can occur due to slow storage devices, high contention between processes, non-optimal I/O schedulers, incorrect caching operation, or virtualization features.
Purpose of iostat and dstat
iostat is a utility from the sysstat package designed to collect detailed statistics on CPU and disk device load. The main task of iostat is to show how intensively a specific disk is being used, whether there is a request queue, and what the average waiting time for operations is.
dstat is a versatile monitoring tool that displays real-time statistics across several subsystems at once: CPU, memory, disk, network, processes. It allows you to correlate disk activity with the overall server load and is convenient for rapid diagnostics.
These utilities complement each other: iostat provides an accurate picture at the device level, while dstat provides the context of the entire system.
Prerequisites and requirements
Before starting the analysis, the following conditions must be met:
- Linux operating system (Debian, Ubuntu, AlmaLinux, Rocky Linux, CentOS).
- SSH access to the server.
- Root privileges or the ability to execute commands via sudo.
Checking the OS version:
cat /etc/os-release
Installing the necessary packages.
Debian / Ubuntu:
sudo apt update
sudo apt install sysstat dstat
CentOS / RHEL / AlmaLinux / Rocky Linux:
sudo yum install sysstat dstat
sudo dnf install sysstat dstat
Checking sysstat operation:
systemctl status sysstat
If the service is active, the relevant information will be displayed:
root@server:~# systemctl status sysstat ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; preset: enabled) Active: active (exited) since Tue 2025-12-23 10:35:35 UTC; 16min ago Docs: man:sa1(8) man:sadc(8) man:sar(1) Main PID: 731 (code=exited, status=0/SUCCESS) CPU: 7ms
Step-by-step review and analysis
Basic disk analysis using iostat
The iostat utility is used to assess CPU and disk subsystem load, as well as to identify I/O delays and queues.
Syntax:
sudo iostat [options] [interval] [count]
Most commonly used parameters:
- -x — extended statistics;
- -d — disk-only data;
- -k — output in kilobytes;
- -p — statistics for partitions or a specific device.
Basic example:
sudo iostat -x
Dynamic analysis:
sudo iostat -xk 5 3
The interval and number of samples allow you to track load changes over time, rather than the average state since system boot.
Example iostat output:
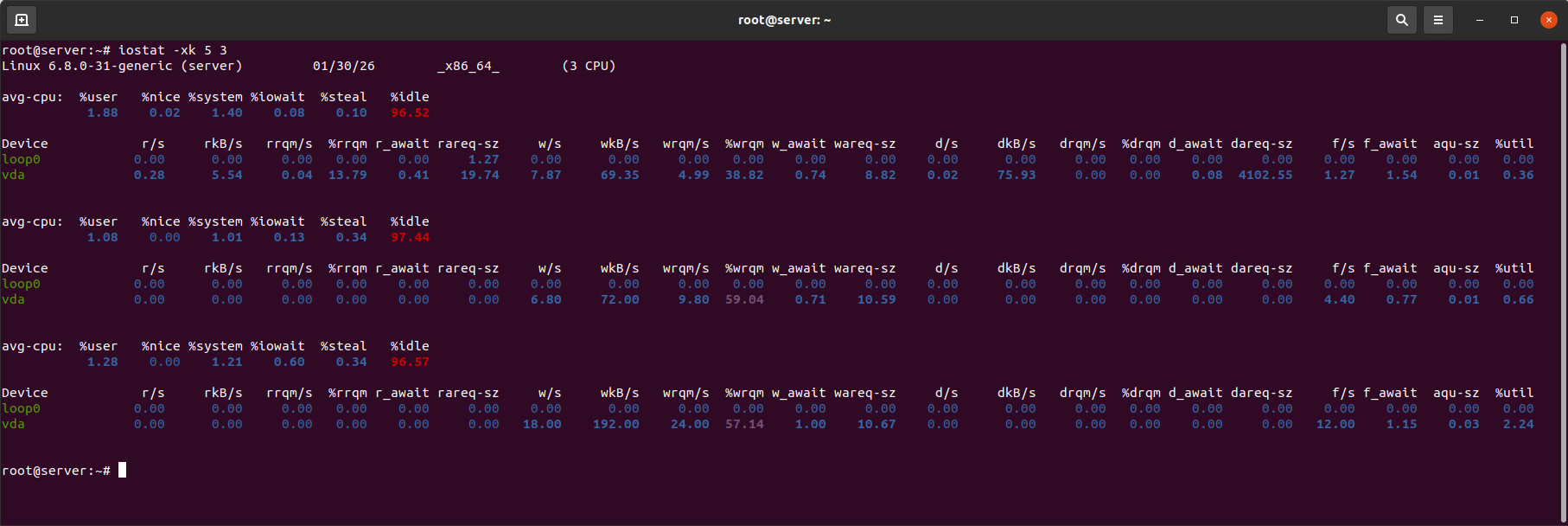
Key CPU metrics:
- %iowait — the percentage of time the CPU is idle while waiting for I/O operations. An increase in this metric indicates the disk's impact on overall performance.
- %steal — relevant for virtual servers and shows stolen CPU time.
Key disk metrics:
- %util — the percentage of time the disk was busy. Values consistently exceeding 80–90% indicate device saturation.
- r_await — the average time (ms) for read operations to complete (including queue time).
- w_await — the average time (ms) for write operations to complete (including queue time).
- aqu-sz — (avg queue size) the average length of the request queue for the disk. A value > 1 already indicates a queue forming. A value > 2–4 for HDD / > 1–2 for SSD is a sign that the disk is not keeping up with the load.
The difference between await and svctm shows whether the delay is caused by the queue, rather than the physical disk speed.
If await only slightly exceeds svctm (difference < 20–30%), delays are mainly caused by the disk itself (slow physical read/write).
If await is significantly greater than svctm (difference > 50–100%), the main delay is caused by the request queue (aqu-sz will be high), indicating disk overload from many parallel requests.
In modern versions of iostat (as in the example), svctm is not displayed because its calculation is unreliable. For analysis, the combination of await + aqu-sz is used: high await with low aqu-sz (~0) indicates a slow disk; high await with high aqu-sz (>1) indicates the disk is overloaded with requests.
Analyzing the overall picture with dstat
dstat is used for real-time system observation and correlating disk load with other resources.
Command examples:
dstat -d
dstat --disk-util
dstat -rd --disk-util
dstat -D vda,sda
Example run with an interval:
dstat -rd --disk-util 1 5
When analyzing, pay attention to:
- increase in iowait in CPU;
- read or write peaks;
- simultaneous network and disk activity (backups, synchronization).
Example dstat output:
dstat -rd --disk-util 1 5 --io/total- -dsk/total- vda- read write| read write|util 0 4.00 | 0 76k|0.50 0 29.5 | 0 240k|0.20 0 1.00 | 0 4096B| 0 0 0 | 0 0 | 0 0 1.00 | 0 32k| 0
Comparison of dstat and iostat:
| Criteria | iostat | dstat |
|---|---|---|
| Data Accuracy | High | High |
| Real-time mode | Limited | Excellent |
| Historical data | Yes (sar) | No |
| Colored output | No | Yes |
| Extensibility | No | Plugins |
| CSV export | No | Yes |
| CPU load | Low | Medium |
dstat is particularly useful for short-term load spikes that are not always noticeable in iostat.
Identifying disk I/O bottlenecks
The following commands are used for quick diagnostics:
sudo iostat -mx 2
sudo iostat -p /dev/vda 2 5
sar -d 1 5
Typical signs of a problem:
- %util above 80% for an extended period;
- await above 20–30 ms for SSD or above 50–100 ms for HDD;
- aqu-sz greater than 2–3, indicating queue buildup.
In the example, the disk /dev/vda is used — this is a virtual disk (VirtIO) on a virtual server. On physical servers and in other environments, disks may be named differently.
- /dev/sdX (e.g., /dev/sda) — regular SATA/SAS/USB disks
- /dev/nvmeXnY (e.g., /dev/nvme0n1) — NVMe drives
- /dev/vdX — virtual disks
Identifying processes causing high disk I/O load
After establishing the presence of disk subsystem overload using iostat and dstat, the next step is to identify the specific processes initiating intensive read or write operations. Analysis at the device level without identifying the load source does not allow for correct remedial actions.
Using iotop
The primary tool for finding processes that are actively using the disk is the iotop utility.
sudo iotop -ao
Command parameters:
- -a — displays cumulative statistics since the process started, which helps identify background tasks with long-term I/O;
- -o — shows only those processes that are currently performing I/O operations.
Example output:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 11056 be/4 mysql 0.00 B 3.44 M 0.00 % 0.76 % mysqld 2580 be/4 rsync 0.00 B 23.48 M 0.00 % 1.17 % rsync
In the iotop output, special attention should be paid to the DISK READ, DISK WRITE fields and the I/O time percentage. Typically, the sources of load are database processes, backup processes, file synchronization processes, or user scripts.
Using pidstat for per-process I/O analysis
For a more formalized and repeatable analysis, pidstat, which is part of the sysstat package, can be used.
pidstat -d 1
This command outputs disk I/O statistics for each process at one-second intervals. This is convenient for identifying short-term activity spikes and correlating them with other system metrics.
pidstat is particularly useful in situations where load appears periodically and may not always be captured by iotop.
Using lsof for file activity analysis
In cases where it is necessary to understand which specific files or directories a process is working with, the lsof utility is used.
lsof +D /path
Where /path is a specific directory within which active files and processes need to be identified. For example, this could be a database directory, a backup directory, or a temporary files area.
The command allows you to determine which processes are currently holding file descriptors and performing operations within the specified path, which is especially useful when analyzing load from applications.
Analyzing the load context
Identifying a process with high disk activity is not the end goal. The administrator needs to assess the context of its operation:
- is the load expected for this service;
- is the process running at an appropriate time (e.g., backups during peak hours);
- can the schedule or operational parameters be changed;
- is it permissible to reduce the I/O priority.
This approach makes it possible to distinguish normal load from problematic load and to choose the correct optimization method.
Verifying the correctness of the analysis
The correctness of the performed analysis is confirmed if:
- peaks in %util, await, or aqu-sz in iostat coincide in time with process activity in iotop or pidstat;
- an increase in iowait in dstat coincides with disk operations, and not with CPU load;
- repeated measurements show a reproducible load pattern.
For data accumulation and subsequent analysis, it is recommended to use logging:
sar -d 1 100 > io.log
This allows you to record the behavior of the disk subsystem over a specified period and use the data when investigating incidents.
Typical mistakes and operational features
In the practice of operating hosting servers, the following problems are most common:
- running backups and data synchronization during peak hours;
- heavy use of swap when there is insufficient RAM;
- an unsuitable I/O scheduler for the drive type;
- lack of prioritization for background tasks.
To reduce the impact of background processes on performance, it is recommended to use the ionice utility to manage the I/O priority of a process, which allows you to lessen the impact of background tasks on system responsiveness.
Example of use:
ionice -c3 rsync /source /destination
Key priorities:
- -c1 (realtime) — the highest priority. Used for latency-critical tasks. Can completely block other processes.
- -c2 (best-effort) — the default for most processes. Allows priority level adjustment (from 0 (high) to 7 (low)).
- -c3 (idle) — background. The process will only get disk access when no other processes are using it. Safe and recommended for background operations (backups, data synchronization).
In this example, the rsync process runs with the lowest I/O priority, minimizing its impact on the core system operations. Using ionice allows you to minimize the impact of background processes without needing to disable them completely.
Conclusion
Monitoring disk I/O is an integral part of maintaining the performance and stability of a server infrastructure. The iostat and dstat utilities allow you to identify overload situations and assess the state of the disk subsystem, while tools like iotop, pidstat, and lsof help identify specific processes and the nature of their load.
Regular application of the described approach, correct interpretation of metrics, and management of I/O priorities help reduce service response times, increase load predictability, and ensure compliance with SLA requirements. Subsequently, this methodology can be expanded through centralized monitoring and automation of I/O load analysis.




















































