
Monitorowanie operacji wejścia/wyjścia na dysku za pomocą iostat i dstat
Wprowadzenie
Monitorowanie wejścia-wyjścia dysku jest jednym z kluczowych zadań podczas obsługi serwerów w infrastrukturze hostingowej. Podsystem dyskowy bezpośrednio wpływa na wydajność usług internetowych, baz danych, maszyn wirtualnych, kontenerów i zadań w tle. Nawet przy wystarczającej ilości pamięci RAM i wolnych zasobach CPU, przeciążony lub wolny dysk może stać się wąskim gardłem całego systemu.
Ten podręcznik jest przeznaczony dla administratorów systemów, inżynierów DevOps i właścicieli serwerów. Obejmuje narzędzia iostat i dstat, zasady ich działania, interpretację metryk oraz praktyczne podejście do znajdowania wąskich gardeł I/O dysku w środowisku hostingowym.
Informacje ogólne i zasady działania
Wejście-wyjście dysku w infrastrukturze serwerowej
Wejście-wyjście dysku obejmuje operacje odczytu i zapisu danych na urządzeniach blokowych. W rzeczywistych scenariuszach hostingu obciążenie podsystemu dyskowego najczęściej generowane jest przez:
- bazy danych (MySQL, MariaDB, PostgreSQL);
- aplikacje internetowe z dynamiczną zawartością;
- usługi pocztowe;
- kopie zapasowe i synchronizację danych;
- logowanie;
- pliki wymiany i tymczasowe;
- skrypty użytkowników i zadania cron.
Wąskie gardła mogą wystąpić z powodu wolnych urządzeń pamięci masowej, wysokiej konkurencji między procesami, nieoptymalnych planistów I/O, nieprawidłowego działania pamięci podręcznej lub funkcji wirtualizacji.
Cel iostat i dstat
iostat to narzędzie z pakietu sysstat zaprojektowane do zbierania szczegółowych statystyk dotyczących obciążenia CPU i urządzeń dyskowych. Głównym zadaniem iostat jest pokazanie, jak intensywnie wykorzystywany jest konkretny dysk, czy istnieje kolejka żądań i jaki jest średni czas oczekiwania na operacje.
dstat to wszechstronne narzędzie monitorujące, które wyświetla statystyki w czasie rzeczywistym w kilku podsystemach jednocześnie: CPU, pamięć, dysk, sieć, procesy. Pozwala na korelację aktywności dysku z ogólnym obciążeniem serwera i jest wygodne do szybkiej diagnostyki.
Te narzędzia się uzupełniają: iostat dostarcza dokładnego obrazu na poziomie urządzenia, podczas gdy dstat zapewnia kontekst całego systemu.
Wymagania wstępne i wymagania
Przed rozpoczęciem analizy muszą być spełnione następujące warunki:
- System operacyjny Linux (Debian, Ubuntu, AlmaLinux, Rocky Linux, CentOS).
- Dostęp SSH do serwera.
- Uprawnienia roota lub możliwość wykonywania poleceń przez sudo.
Sprawdzanie wersji systemu operacyjnego:
cat /etc/os-release
Instalacja niezbędnych pakietów.
Debian / Ubuntu:
sudo apt update
sudo apt install sysstat dstat
CentOS / RHEL / AlmaLinux / Rocky Linux:
sudo yum install sysstat dstat
sudo dnf install sysstat dstat
Sprawdzanie działania sysstat:
systemctl status sysstat
Jeśli usługa jest aktywna, zostaną wyświetlone odpowiednie informacje:
root@server:~# systemctl status sysstat ● sysstat.service - Resets System Activity Logs Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; preset: enabled) Active: active (exited) since Tue 2025-12-23 10:35:35 UTC; 16min ago Docs: man:sa1(8) man:sadc(8) man:sar(1) Main PID: 731 (code=exited, status=0/SUCCESS) CPU: 7ms
Przegląd i analiza krok po kroku
Podstawowa analiza dysku za pomocą iostat
Narzędzie iostat służy do oceny obciążenia CPU i podsystemu dyskowego oraz do identyfikacji opóźnień I/O i kolejek.
Składnia:
sudo iostat [opcje] [interwał] [liczba]
Najczęściej używane parametry:
- -x — rozszerzone statystyki;
- -d — dane tylko dla dysków;
- -k — wyjście w kilobajtach;
- -p — statystyki dla partycji lub konkretnego urządzenia.
Podstawowy przykład:
sudo iostat -x
Analiza dynamiczna:
sudo iostat -xk 5 3
Interwał i liczba próbek pozwalają śledzić zmiany obciążenia w czasie, a nie średni stan od uruchomienia systemu.
Przykład wyjścia iostat:
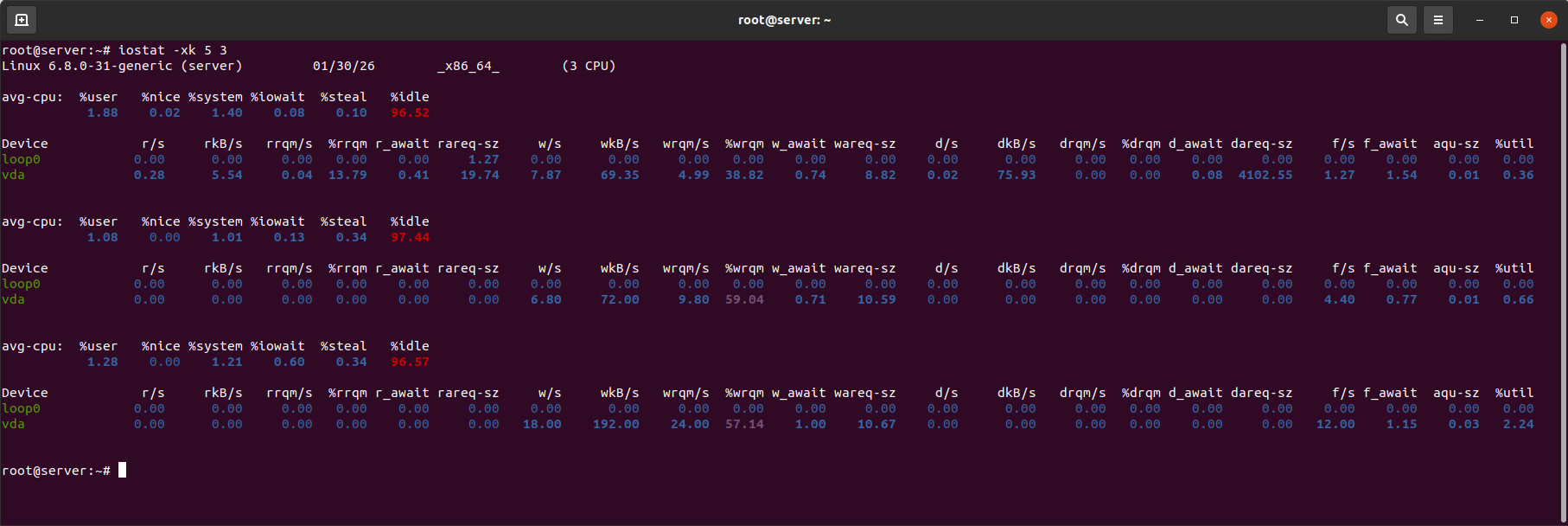
Kluczowe metryki CPU:
- %iowait — procent czasu, gdy CPU jest bezczynne, czekając na operacje I/O. Wzrost tej metryki wskazuje na wpływ dysku na ogólną wydajność.
- %steal — istotne dla serwerów wirtualnych i pokazuje skradziony czas CPU.
Kluczowe metryki dysku:
- %util — procent czasu, gdy dysk był zajęty. Wartości stale przekraczające 80–90% wskazują na nasycenie urządzenia.
- r_await — średni czas (ms) na zakończenie operacji odczytu (w tym czas w kolejce).
- w_await — średni czas (ms) na zakończenie operacji zapisu (w tym czas w kolejce).
- aqu-sz — (średnia wielkość kolejki) średnia długość kolejki żądań dla dysku. Wartość > 1 już wskazuje na tworzenie się kolejki. Wartość > 2–4 dla HDD / > 1–2 dla SSD to znak, że dysk nie nadąża z obciążeniem.
Różnica między await a svctm pokazuje, czy opóźnienie jest spowodowane przez kolejkę, a nie przez fizyczną prędkość dysku.
Jeśli await tylko nieznacznie przekracza svctm (różnica < 20–30%), opóźnienia są głównie spowodowane przez sam dysk (wolny fizyczny odczyt/zapis).
Jeśli await znacznie przekracza svctm (różnica > 50–100%), główne opóźnienie jest spowodowane przez kolejkę żądań (aqu-sz będzie wysokie), co wskazuje na przeciążenie dysku przez wiele równoległych żądań.
W nowoczesnych wersjach iostat (jak w przykładzie) svctm nie jest wyświetlane, ponieważ jego obliczenia są niewiarygodne. Do analizy używa się kombinacji await + aqu-sz: wysokie await z niskim aqu-sz (~0) wskazuje na wolny dysk; wysokie await z wysokim aqu-sz (>1) wskazuje na przeciążenie dysku żądaniami.
Analiza ogólnego obrazu za pomocą dstat
dstat jest używany do obserwacji systemu w czasie rzeczywistym i korelacji obciążenia dysku z innymi zasobami.
Przykłady poleceń:
dstat -d
dstat --disk-util
dstat -rd --disk-util
dstat -D vda,sda
Przykład uruchomienia z interwałem:
dstat -rd --disk-util 1 5
Podczas analizy zwróć uwagę na:
- wzrost iowait w CPU;
- szczyty odczytu lub zapisu;
- jednoczesną aktywność sieciową i dyskową (kopie zapasowe, synchronizacja).
Przykład wyjścia dstat:
dstat -rd --disk-util 1 5 --io/total- -dsk/total- vda- read write| read write|util 0 4.00 | 0 76k|0.50 0 29.5 | 0 240k|0.20 0 1.00 | 0 4096B| 0 0 0 | 0 0 | 0 0 1.00 | 0 32k| 0
Porównanie dstat i iostat:
| Kryteria | iostat | dstat |
|---|---|---|
| Dokładność danych | Wysoka | Wysoka |
| Tryb rzeczywisty | Ograniczony | Doskonały |
| Dane historyczne | Tak (sar) | Nie |
| Kolorowe wyjście | Nie | Tak |
| Rozszerzalność | Nie | Wtyczki |
| Eksport CSV | Nie | Tak |
| Obciążenie CPU | Niskie | Średnie |
dstat jest szczególnie przydatny do krótkoterminowych skoków obciążenia, które nie zawsze są zauważalne w iostat.
Identyfikacja wąskich gardeł I/O dysku
Następujące polecenia są używane do szybkiej diagnostyki:
sudo iostat -mx 2
sudo iostat -p /dev/vda 2 5
sar -d 1 5
Typowe oznaki problemu:
- %util powyżej 80% przez dłuższy czas;
- await powyżej 20–30 ms dla SSD lub powyżej 50–100 ms dla HDD;
- aqu-sz większe niż 2–3, wskazujące na tworzenie się kolejki.
W przykładzie używany jest dysk /dev/vda — jest to dysk wirtualny (VirtIO) na serwerze wirtualnym. Na serwerach fizycznych i w innych środowiskach dyski mogą być nazwane inaczej.
- /dev/sdX (np. /dev/sda) — zwykłe dyski SATA/SAS/USB
- /dev/nvmeXnY (np. /dev/nvme0n1) — dyski NVMe
- /dev/vdX — dyski wirtualne
Identyfikacja procesów powodujących wysokie obciążenie I/O dysku
Po ustaleniu obecności przeciążenia podsystemu dyskowego za pomocą iostat i dstat, kolejnym krokiem jest identyfikacja konkretnych procesów inicjujących intensywne operacje odczytu lub zapisu. Analiza na poziomie urządzenia bez identyfikacji źródła obciążenia nie pozwala na podjęcie właściwych działań naprawczych.
Użycie iotop
Głównym narzędziem do znajdowania procesów aktywnie korzystających z dysku jest narzędzie iotop.
sudo iotop -ao
Parametry polecenia:
- -a — wyświetla skumulowane statystyki od momentu uruchomienia procesu, co pomaga zidentyfikować zadania w tle z długoterminowym I/O;
- -o — pokazuje tylko te procesy, które aktualnie wykonują operacje I/O.
Przykład wyjścia:
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 11056 be/4 mysql 0.00 B 3.44 M 0.00 % 0.76 % mysqld 2580 be/4 rsync 0.00 B 23.48 M 0.00 % 1.17 % rsync
W wyjściu iotop szczególną uwagę należy zwrócić na pola DISK READ, DISK WRITE i procent czasu I/O. Zazwyczaj źródłami obciążenia są procesy baz danych, procesy tworzenia kopii zapasowych, procesy synchronizacji plików lub skrypty użytkowników.
Użycie pidstat do analizy I/O na proces
Do bardziej sformalizowanej i powtarzalnej analizy można użyć pidstat, który jest częścią pakietu sysstat.
pidstat -d 1
To polecenie wyświetla statystyki I/O dysku dla każdego procesu w odstępach jednosekundowych. Jest to wygodne do identyfikacji krótkoterminowych skoków aktywności i korelacji ich z innymi metrykami systemowymi.
pidstat jest szczególnie przydatny w sytuacjach, gdy obciążenie pojawia się okresowo i nie zawsze jest uchwycone przez iotop.
Użycie lsof do analizy aktywności plików
W przypadkach, gdy konieczne jest zrozumienie, z którymi konkretnymi plikami lub katalogami pracuje proces, używa się narzędzia lsof.
lsof +D /path
Gdzie /path to konkretny katalog, w którym należy zidentyfikować aktywne pliki i procesy. Na przykład może to być katalog bazy danych, katalog kopii zapasowych lub obszar plików tymczasowych.
Polecenie pozwala określić, które procesy aktualnie trzymają deskryptory plików i wykonują operacje w określonej ścieżce, co jest szczególnie przydatne przy analizie obciążenia z aplikacji.
Analiza kontekstu obciążenia
Identyfikacja procesu z wysoką aktywnością dysku nie jest celem końcowym. Administrator musi ocenić kontekst jego działania:
- czy obciążenie jest oczekiwane dla tej usługi;
- czy proces działa w odpowiednim czasie (np. kopie zapasowe w godzinach szczytu);
- czy można zmienić harmonogram lub parametry operacyjne;
- czy dopuszczalne jest zmniejszenie priorytetu I/O.
Takie podejście pozwala odróżnić normalne obciążenie od problematycznego i wybrać właściwą metodę optymalizacji.
Weryfikacja poprawności analizy
Poprawność przeprowadzonej analizy jest potwierdzona, jeśli:
- szczyty w %util, await lub aqu-sz w iostat pokrywają się w czasie z aktywnością procesów w iotop lub pidstat;
- wzrost iowait w dstat pokrywa się z operacjami dyskowymi, a nie z obciążeniem CPU;
- powtarzane pomiary pokazują powtarzalny wzorzec obciążenia.
Do gromadzenia danych i późniejszej analizy zaleca się użycie logowania:
sar -d 1 100 > io.log
Pozwala to na rejestrowanie zachowania podsystemu dyskowego w określonym okresie i wykorzystanie danych podczas badania incydentów.
Typowe błędy i cechy operacyjne
W praktyce obsługi serwerów hostingowych najczęściej występują następujące problemy:
- uruchamianie kopii zapasowych i synchronizacji danych w godzinach szczytu;
- intensywne użycie swap przy niewystarczającej ilości pamięci RAM;
- nieodpowiedni planista I/O dla typu dysku;
- brak priorytetyzacji zadań w tle.
Aby zmniejszyć wpływ procesów w tle na wydajność, zaleca się użycie narzędzia ionice do zarządzania priorytetem I/O procesu, co pozwala zmniejszyć wpływ zadań w tle na responsywność systemu.
Przykład użycia:
ionice -c3 rsync /source /destination
Kluczowe priorytety:
- -c1 (realtime) — najwyższy priorytet. Używany do zadań krytycznych pod względem opóźnień. Może całkowicie zablokować inne procesy.
- -c2 (best-effort) — domyślny dla większości procesów. Pozwala na regulację poziomu priorytetu (od 0 (wysoki) do 7 (niski)).
- -c3 (idle) — w tle. Proces uzyska dostęp do dysku tylko wtedy, gdy żadne inne procesy go nie używają. Bezpieczne i zalecane dla operacji w tle (kopie zapasowe, synchronizacja danych).
W tym przykładzie proces rsync działa z najniższym priorytetem I/O, minimalizując jego wpływ na podstawowe operacje systemowe. Użycie ionice pozwala zminimalizować wpływ procesów w tle bez konieczności ich całkowitego wyłączania.
Podsumowanie
Monitorowanie I/O dysku jest integralną częścią utrzymania wydajności i stabilności infrastruktury serwerowej. Narzędzia iostat i dstat pozwalają zidentyfikować sytuacje przeciążenia i ocenić stan podsystemu dyskowego, podczas gdy narzędzia takie jak iotop, pidstat i lsof pomagają zidentyfikować konkretne procesy i charakter ich obciążenia.
Regularne stosowanie opisanego podejścia, poprawna interpretacja metryk i zarządzanie priorytetami I/O pomagają skrócić czas odpowiedzi usług, zwiększyć przewidywalność obciążenia i zapewnić zgodność z wymaganiami SLA. Następnie tę metodologię można rozszerzyć poprzez scentralizowane monitorowanie i automatyzację analizy obciążenia I/O.




















































