
Diagnose einer hohen Auslastung auf einem VPS
Verwendung von htop, top und iotop-c, um den schuldigen Prozess zu finden
Wenn Ihr VPS anfängt zu stocken – SSH fühlt sich verzögert an, Websites reagieren langsam oder sogar das Tippen im Terminal scheint träge – bedeutet das normalerweise, dass eine oder mehrere Systemressourcen (CPU, RAM oder Festplatten-I/O) an ihre Grenzen stoßen. Diese Anleitung führt Sie durch einen praktischen, schrittweisen Prozess, um herauszufinden, was passiert und welcher Prozess schuld ist, indem Sie drei Standard-Linux-Tools verwenden: htop, top und iotop-c.
Die Zielgruppe sind Anfänger bis fortgeschrittene Systemadministratoren, die mit der Befehlszeile und grundlegenden Linux-Konzepten vertraut sind.
Schritt eins: Wissen, was "hohe Last" tatsächlich bedeutet
Viele Menschen sehen einen hohen "Load Average" und geraten in Panik – aber nicht alle hohen Lasten sind schlecht. Lassen Sie uns das klären.
Was ist der "Load Average"?
Der "Load Average" zeigt Ihnen, wie viele Prozesse zu einem bestimmten Zeitpunkt auf die CPU warten. Er wird als drei Zahlen angezeigt (für die letzten 1, 5 und 15 Minuten).
Beispiel: uptime
Ausgabe:
17:41:25 up 2 days, 3:45, 1 user, load average: 2.34, 1.89, 1.42
Interpretation:
- 2.34 – durchschnittliche Last in der letzten Minute
- 1.89 – in den letzten 5 Minuten
- 1.42 – in den letzten 15 Minuten
Vergleichen Sie diese Zahlen nun mit Ihrer CPU-Kernanzahl. Wenn Sie 2 Kerne haben:
- Eine Last um 2.0 bedeutet, dass beide CPUs voll ausgelastet sind – das System ist beschäftigt, aber in Ordnung.
- Eine Last deutlich höher als 2.0 (wie 3 oder 4) bedeutet, dass es eine Warteschlange gibt – zu viele Prozesse warten.
Überprüfen Sie, wie viele Kerne Sie haben:
nproc
Wenn die Last ≫ Anzahl der Kerne für längere Zeit, ist es Zeit zu untersuchen.
Schritt zwei: Einen schnellen Überblick mit htop bekommen
htop ist der einfachste Weg, um in Echtzeit zu visualisieren, was in Ihrem VPS vor sich geht.
htop installieren
Verwenden Sie den für Ihre Linux-Distribution geeigneten Befehl zur Installation:
sudo apt install htopfür Ubuntu/Debiansudo yum install htopfür CentOS/RHEL
Ausführen
Führen Sie den Befehl htop aus. Sie sehen eine bunte Oberfläche wie diese:
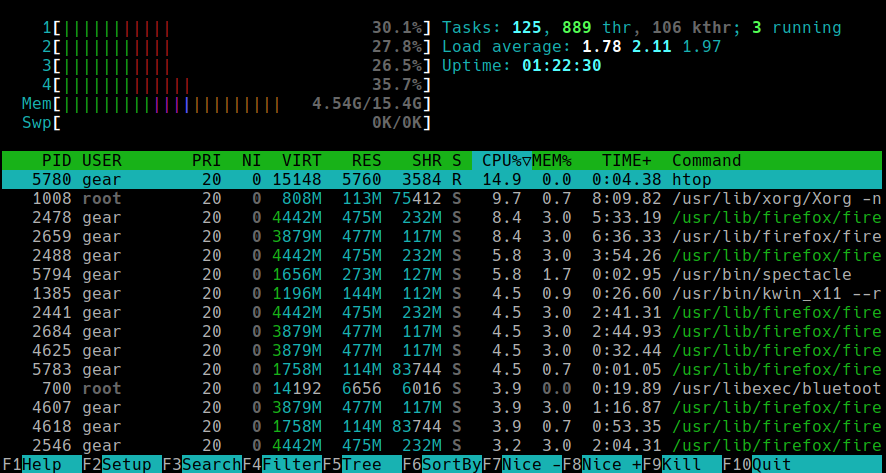
Das Layout verstehen
- Obere Balken zeigen die CPU-, Speicher- und Swap-Nutzung in Echtzeit.
- Load Average ist in der oberen rechten Ecke sichtbar.
- Die Prozessliste zeigt, was läuft und wie viel CPU und RAM jeder Prozess verwendet.
Navigations-Tipps
- Nach CPU-Nutzung sortieren: Drücken Sie F6, dann wählen Sie "PERCENT_CPU"
- Nach Speicher sortieren: Drücken Sie F6, wählen Sie "PERCENT_MEM"
- Baumansicht (Eltern-/Kindprozesse anzeigen): Drücken Sie F5
- Einen Prozess beenden: Markieren Sie ihn – drücken Sie F9 – wählen Sie das Signal (Standard ist 15, "beenden")
- Nach einem Prozess suchen: Drücken Sie F3, geben Sie einen Teil seines Namens ein (z.B. "nginx")
Worauf zu achten ist
- Prozesse mit hohem CPU% – diese verbrauchen die meiste CPU-Zeit.
- Prozesse mit hohem MEM% – diese verbrauchen RAM und könnten das System zum Swappen zwingen.
- Wenn ein Prozess alle paar Sekunden wieder oben erscheint, könnte es sich um ein Schleifenskript oder einen neu startenden Dienst handeln.
Beispiel
Führen Sie htop aus. Wenn Sie etwas wie das Folgende sehen:
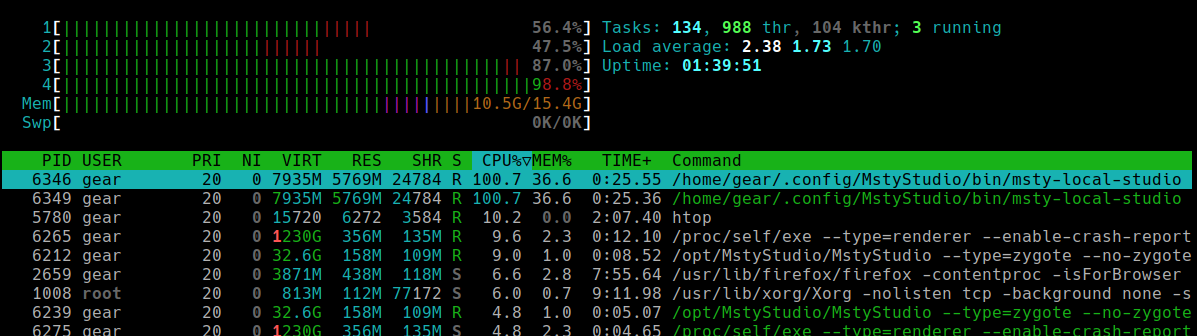
Es ist klar, dass msty-local-studio mit PID 6346 mehr CPU und Speicher verwendet als alles andere. Jetzt wissen Sie, worauf Sie sich bei Ihren nächsten Überprüfungen konzentrieren müssen.
Schritt drei: Mit top gegenprüfen
Während htop benutzerfreundlich ist, ist top auf jedem Linux-System verfügbar – keine Installation erforderlich. Es ist eine gute Rückfallebene, wenn Sie nur SSH-Zugriff auf eine minimale Umgebung haben.
Ausführen
Führen Sie den Befehl top aus. Sie sehen eine Oberfläche wie diese:
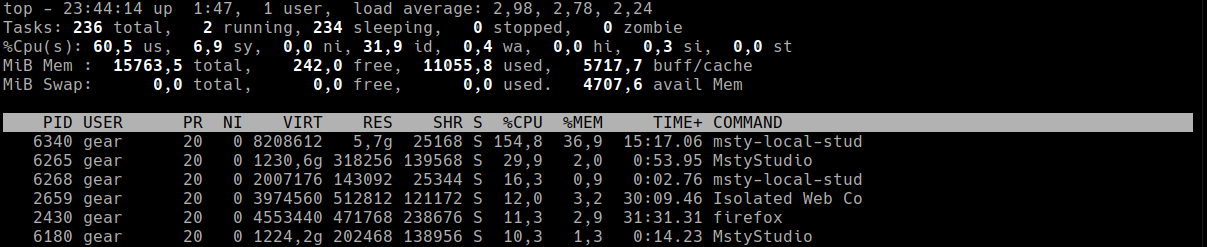
Wichtige Punkte
- Die Zeile %Cpu(s) zeigt, wohin die CPU-Zeit geht:
- us – Benutzerprozesse
- sy – System-/Kernelaufgaben
- wa – Warten auf I/O (Festplatte)
- %wa (I/O-Wartezeit) über 10–15% bedeutet oft einen Festplattenengpass.
- Load Average und Aufgaben-Zusammenfassung zeigen, wie beschäftigt das System ist.
Nützliche Tastenkombinationen
- Shift + P – nach CPU sortieren
- Shift + M – nach Speicher sortieren
- Shift + T – nach Prozesslaufzeit sortieren
- 1 – CPU-Nutzung pro Kern umschalten
- k – einen Prozess beenden (PID eingeben, wenn gefragt)
- q –
topbeenden
Wann top verwenden
Verwenden Sie top, wenn:
htopnicht installiert ist (wie in einem Rettungssystem oder Docker-Container).- Sie ein leichtes Tool möchten, das das Gleichgewicht zwischen CPU und I/O in Echtzeit zeigt.
Schritt vier: Wenn CPU und RAM in Ordnung sind – Festplatten-I/O mit iotop-c überprüfen
Manchmal sieht alles normal aus – die CPU-Auslastung ist nicht hoch, der Speicher ist in Ordnung – und doch fühlt sich das System eingefroren an. Befehle wie ls oder cd hängen für Sekunden, und der Load Average ist immer noch hoch. Das ist ein klassisches Zeichen für I/O-Wartezeit, bei der die CPU im Leerlauf ist, aber auf den Abschluss von Festplattenoperationen wartet.
iotop-c installieren
Verwenden Sie den für Ihre Linux-Distribution geeigneten Befehl zur Installation:
sudo apt install iotop-cfür Ubuntu/Debiansudo yum install iotop-cfür CentOS/RHEL
Aktivieren Sie die I/O-Überwachung mit dem Befehl:
sudo sysctl kernel.task_delayacct=1
Ausführen
Führen Sie den Befehl als Root-Benutzer aus: sudo iotop-c. Sie sehen eine Oberfläche wie diese:
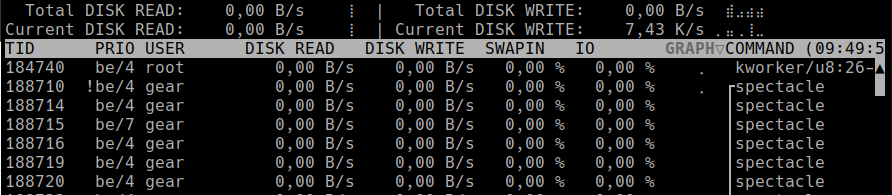
Interpretation
- Die IO-Spalte zeigt, wie viel Zeit jeder Prozess blockiert ist und auf I/O wartet.
- Hohe IO (z.B. 90–100%) – dieser Prozess wartet stark auf die Festplatte.
- Überprüfen Sie, ob Sie Backups, große Datenimporte oder Komprimierungsaufträge ausführen.
Häufige Ursachen für I/O-Überlastung
- Datenbank (
mysqld,postgres), die eine große Abfrage ausführt. - Backup-Skripte (
rsync,tar,dd), die massive Dateien kopieren. - Logdateien, die unkontrolliert in
/var/logwachsen. - Fehlkonfigurierter Swap – wenn das System stark swappt, belastet es die Festplatte.
Schritt fünf: Was Sie gefunden haben, korrelieren
Jetzt, da Sie htop, top und iotop-c verwendet haben, ist es an der Zeit, das Puzzle zusammenzusetzen.
| Symptom | Wahrscheinliche Ursache | Tool zur Überprüfung |
|---|---|---|
| Hohe CPU-Auslastung | Fehlerhaftes Skript, schwerer Prozess | htop, top |
| Hohe Speicherauslastung | Speicherleck, zu viele Worker | htop |
| Hohe I/O-Wartezeit, langsame Reaktion | Festplattenengpass, Swapping | iotop-c, top |
| Hohe Last, aber CPU im Leerlauf | I/O- oder Speicherauslastung | top, iotop-c |
Überprüfen Sie auch die Systemprotokolle auf Warnungen:
journalctl -xe
oder:
tail -n 50 /var/log/syslog
Sie könnten Nachrichten über Kernel-Fehler, fehlgeschlagene Einbindungen oder Prozesse finden, die vom OOM-Killer (Out Of Memory) beendet wurden.
Schritt sechs: Maßnahmen ergreifen
Sobald Sie den Schuldigen identifiziert haben, entscheiden Sie, was als Nächstes zu tun ist.
Den Prozess neu starten oder stoppen
sudo systemctl restart <service>
oder, falls erforderlich:
sudo kill -9 <pid>
Festplattenspeicher freigeben
Wenn die Festplattennutzung hoch ist, verwenden Sie df -h, um festzustellen, welche Partition bereinigt werden soll, oder sudo du -sh /var/log/*, um festzustellen, welche Protokolle bereinigt werden sollen.
Prozesslast reduzieren
- Begrenzen Sie Cron-Jobs, damit sie nicht gleichzeitig ausgeführt werden.
- Passen Sie die Datenbankabfragelimits oder das Caching an.
- Reduzieren Sie die Anzahl der Worker in Nginx, Apache oder Gunicorn.
Wenn nichts hilft – Ressourcen aufrüsten
Wenn Sie ständig an Grenzen stoßen, selbst bei optimierten Arbeitslasten, ist es an der Zeit, mehr CPU, RAM hinzuzufügen oder auf schnelleren Speicher umzusteigen (z.B. von SSD zu NVMe).
Schritt sieben: Prävention und kontinuierliche Überwachung
Sie sollten nicht jedes Mal manuell einloggen und die Last überprüfen müssen. Sie können Überwachung und Alarme mit Tools wie: glances, netdata, prometheus, etc. einrichten.
Schnellreferenzbefehle
| Ziel | Befehl |
|---|---|
| Load Average anzeigen | uptime |
| CPU-/Speicherlast visuell anzeigen | htop |
| Minimale Prozessansicht | top |
| Festplattenaktivität überwachen | iotop-c |
| Protokolle anzeigen | journalctl -xe |
Praxisbeispiel: Das durchgegangene Backup-Skript
Lassen Sie uns alles mit einem realen Szenario zusammenfügen.
Situation
- VPS mit 2 CPU-Kernen und SSD-Speicher
- Plötzlich sehr langsam – SSH-Verzögerung, Webseiten-Timeout
uptimezeigt: load average: 8.5, 7.3, 6.9 – viel zu hoch für 2 Kerne.
Untersuchung
- Führen Sie
htopaus: Die CPU-Auslastung ist niedrig – nur 10–15%. Die Speicherauslastung ist in Ordnung. Also nicht CPU-gebunden. - Führen Sie
topaus: %wa = 40% – System wartet auf Festplatten-I/O. - Führen Sie
iotop-caus:
Bingo – ein Backup-Skript, das ein riesiges Verzeichnis direkt auf der Festplatte komprimiert.
Behebung
- Stoppen oder verschieben Sie das Backup, um es nachts auszuführen.
- Komprimieren Sie in
/tmp(im Speicher), bevor Sie es auf die Festplatte verschieben. - Verwenden Sie
ionice, um seine Festplattenpriorität zu reduzieren.
Ergebnis
Die VPS-Leistung kehrt sofort zur Normalität zurück.
Abschließende Gedanken
Die Diagnose einer hohen Last ist keine Magie – es geht darum, systematisch CPU, Speicher und Festplatte nacheinander zu überprüfen. Verwenden Sie Ihre Tools wie ein Detektiv:
- Ist die CPU ausgelastet? –
htop,top - Ist der Speicher voll oder swappt? –
htop,top - Ist die Festplatte überlastet? –
iotop-c - Bestätigen die Protokolle es? –
journalctl
Sobald Sie den schuldigen Prozess identifiziert haben, können Sie entscheiden: optimieren, beenden oder besser planen. Mit der Zeit werden Sie Muster erkennen – ein Prozess mit hoher Last, zu viele Cron-Jobs oder eine falsch konfigurierte Webanwendung. Dann hören Sie auf, Brände zu löschen, und beginnen, wie ein echter Systemadministrator zu verwalten.




















































