
Diagnozowanie wysokiego obciążenia na VPS
Używanie htop, top i iotop-c do znalezienia winnego procesu
Kiedy Twój VPS zaczyna się zacinać – SSH działa z opóźnieniem, strony internetowe reagują wolno, a nawet pisanie w terminalu wydaje się powolne – zazwyczaj oznacza to, że jeden lub więcej zasobów systemowych (CPU, RAM lub dysk I/O) jest wykorzystywanych do granic możliwości. Ten przewodnik przeprowadzi Cię przez praktyczny, krok po kroku proces identyfikacji, co się dzieje i który proces jest winny, używając trzech standardowych narzędzi Linux: htop, top i iotop-c.
Zakłada się, że odbiorcą są początkujący do średniozaawansowanych administratorzy systemów, którzy znają linię poleceń i podstawowe pojęcia Linux.
Krok pierwszy: Zrozum, co naprawdę oznacza "wysokie obciążenie"
Wiele osób widzi wysoką "średnią obciążenia" i wpada w panikę – ale nie wszystkie wysokie obciążenia są złe. Wyjaśnijmy to.
Co to jest "średnia obciążenia"?
"Średnia obciążenia" mówi Ci, ile procesów czeka na CPU w danym momencie. Jest wyświetlana jako trzy liczby (dla ostatnich 1, 5 i 15 minut).
Przykład: uptime
Wynik:
17:41:25 up 2 days, 3:45, 1 user, load average: 2.34, 1.89, 1.42
Interpretacja:
- 2.34 – średnie obciążenie w ostatniej minucie
- 1.89 – w ostatnich 5 minutach
- 1.42 – w ostatnich 15 minutach
Teraz porównaj te liczby z liczbą rdzeni CPU. Jeśli masz 2 rdzenie:
- Obciążenie około 2.0 oznacza, że oba CPU są w pełni wykorzystywane – system jest zajęty, ale w porządku.
- Obciążenie znacznie wyższe niż 2.0 (jak 3 lub 4) oznacza, że jest kolejka – zbyt wiele procesów czeka.
Sprawdź, ile masz rdzeni:
nproc
Jeśli obciążenie ≫ liczba rdzeni przez długi czas, czas na dochodzenie.
Krok drugi: Uzyskaj szybki przegląd za pomocą htop
htop to najłatwiejszy sposób na wizualizację, co dzieje się wewnątrz Twojego VPS w czasie rzeczywistym.
Zainstaluj htop
Użyj polecenia odpowiedniego dla Twojej dystrybucji Linux, aby zainstalować:
sudo apt install htopdla Ubuntu/Debiansudo yum install htopdla CentOS/RHEL
Uruchom
Uruchom polecenie htop. Zobaczysz kolorowy interfejs jak ten:
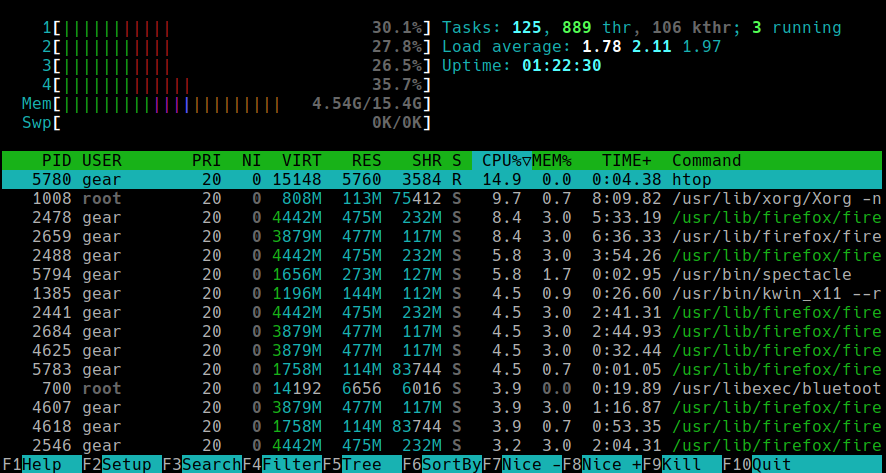
Zrozumienie układu
- Górne paski pokazują użycie CPU, pamięci i swapu w czasie rzeczywistym.
- Średnia obciążenia jest widoczna w prawym górnym rogu.
- Lista procesów pokazuje, co jest uruchomione i ile CPU i RAM zużywa każdy proces.
Wskazówki nawigacyjne
- Sortuj według użycia CPU: naciśnij F6, a następnie wybierz "PERCENT_CPU"
- Sortuj według pamięci: naciśnij F6, wybierz "PERCENT_MEM"
- Widok drzewa (pokaż procesy rodzic/dziecko): naciśnij F5
- Zabij proces: zaznacz go – naciśnij F9 – wybierz sygnał (domyślnie 15, "terminate")
- Szukaj procesu: naciśnij F3, wpisz część jego nazwy (np. "nginx")
Na co zwrócić uwagę
- Procesy z wysokim CPU% – te zużywają najwięcej czasu CPU.
- Procesy z wysokim MEM% – te zużywają RAM i mogą zmuszać system do swapowania.
- Jeśli proces ciągle pojawia się na górze co kilka sekund, może to być skrypt w pętli lub restartująca się usługa.
Przykład
Uruchom htop. Jeśli zobaczysz coś takiego:
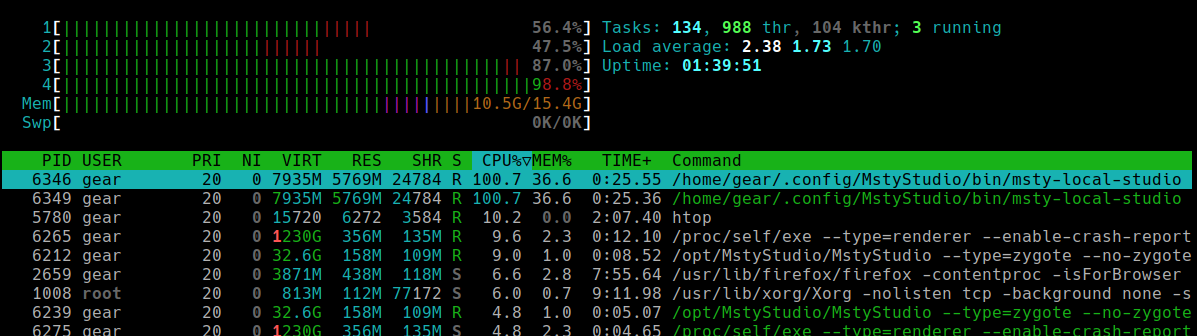
Jest jasne, że msty-local-studio z PID 6346 zużywa więcej CPU i pamięci niż wszystko inne. Teraz wiesz, na czym skupić kolejne kontrole.
Krok trzeci: Sprawdź za pomocą top
Podczas gdy htop jest przyjazny, top jest dostępny na każdym systemie Linux – nie wymaga instalacji. To dobry wybór, gdy masz tylko dostęp SSH do minimalnego środowiska.
Uruchom
Uruchom polecenie top. Zobaczysz interfejs jak ten:
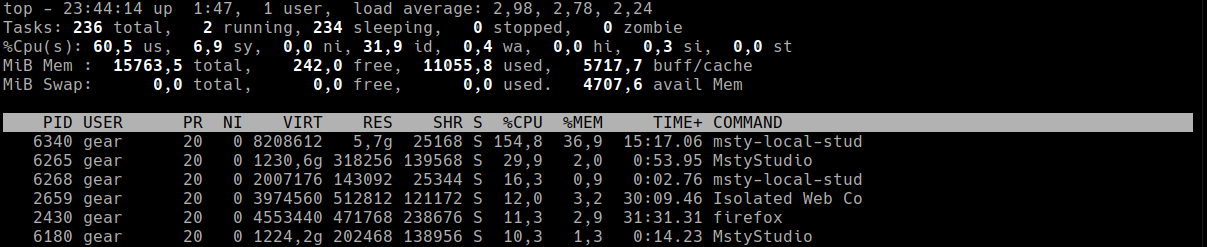
Kluczowe punkty
- Linia %Cpu(s) pokazuje, gdzie idzie czas CPU:
- us – procesy użytkownika
- sy – zadania systemowe/jądra
- wa – oczekiwanie na I/O (dysk)
- %wa (oczekiwanie na I/O) powyżej 10–15% często oznacza wąskie gardło dysku.
- Średnia obciążenia i podsumowanie zadań mówią, jak zajęty jest system.
Przydatne skróty klawiszowe
- Shift + P – sortuj według CPU
- Shift + M – sortuj według pamięci
- Shift + T – sortuj według czasu działania procesu
- 1 – przełącz użycie CPU na rdzeń
- k – zabij proces (wprowadź PID, gdy zostaniesz o to poproszony)
- q – zakończ
top
Kiedy używać top
Używaj top, gdy:
htopnie jest zainstalowany (jak w systemie ratunkowym lub kontenerze Docker).- Chcesz lekkiego narzędzia, które pokazuje równowagę CPU vs. I/O w czasie rzeczywistym.
Krok czwarty: Jeśli CPU i RAM wyglądają dobrze – sprawdź dysk I/O za pomocą iotop-c
Czasami wszystko wygląda normalnie – użycie CPU nie jest wysokie, pamięć jest w porządku – a jednak system wydaje się zamrożony. Polecenia takie jak ls lub cd zawieszają się na kilka sekund, a średnia obciążenia jest nadal wysoka. To klasyczny znak oczekiwania na I/O, gdzie CPU jest bezczynne, ale czeka na zakończenie operacji dyskowych.
Zainstaluj iotop-c
Użyj polecenia odpowiedniego dla Twojej dystrybucji Linux, aby zainstalować:
sudo apt install iotop-cdla Ubuntu/Debiansudo yum install iotop-cdla CentOS/RHEL
Włącz monitorowanie IO za pomocą polecenia:
sudo sysctl kernel.task_delayacct=1
Uruchom
Uruchom polecenie jako użytkownik root: sudo iotop-c. Zobaczysz interfejs jak ten:
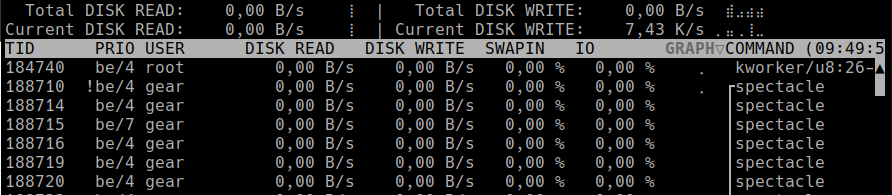
Interpretacja
- Kolumna IO pokazuje, ile czasu każdy proces jest zablokowany, czekając na I/O.
- Wysokie IO (np. 90–100%) – ten proces mocno czeka na dysk.
- Sprawdź, czy uruchamiasz kopie zapasowe, duże importy danych lub zadania kompresji.
Typowe przyczyny przeciążenia I/O
- Baza danych (
mysqld,postgres) wykonująca duże zapytanie. - Skrypty kopii zapasowych (
rsync,tar,dd) kopiujące ogromne pliki. - Pliki dziennika rosnące niekontrolowanie w
/var/log. - Źle skonfigurowany swap – jeśli system zaczyna intensywnie swapować, obciąża dysk.
Krok piąty: Koreluj to, co znalazłeś
Teraz, gdy użyłeś htop, top i iotop-c, czas złożyć puzzle w całość.
| Objaw | Prawdopodobna przyczyna | Narzędzie do sprawdzenia |
|---|---|---|
| Wysokie użycie CPU | Błędny skrypt, ciężki proces | htop, top |
| Wysokie użycie pamięci | Wycieki pamięci, zbyt wiele pracowników | htop |
| Wysokie oczekiwanie na I/O, wolna odpowiedź | Wąskie gardło dysku, swapowanie | iotop-c, top |
| Wysokie obciążenie, ale CPU bezczynne | Wyczerpanie I/O lub pamięci | top, iotop-c |
Sprawdź także dzienniki systemowe pod kątem ostrzeżeń:
journalctl -xe
lub:
tail -n 50 /var/log/syslog
Możesz znaleźć wiadomości o błędach jądra, nieudanych montażach lub procesach zabitych przez OOM (Out Of Memory) killer.
Krok szósty: Podejmij działania
Gdy zidentyfikujesz winowajcę, zdecyduj, co zrobić dalej.
Zrestartuj lub zatrzymaj proces
sudo systemctl restart <service>
lub, jeśli to konieczne:
sudo kill -9 <pid>
Zwolnij miejsce na dysku
Jeśli użycie dysku jest wysokie, użyj df -h, aby określić, którą partycję wyczyścić, lub sudo du -sh /var/log/*, aby określić, które dzienniki wyczyścić.
Zmniejsz obciążenie procesów
- Ogranicz zadania cron, aby nie uruchamiały się jednocześnie.
- Dostosuj limity zapytań do bazy danych lub buforowanie.
- Zmniejsz liczbę pracowników w Nginx, Apache lub Gunicorn.
Jeśli nic nie pomaga – zaktualizuj zasoby
Jeśli ciągle osiągasz limity nawet przy zoptymalizowanych obciążeniach, czas dodać więcej CPU, RAM lub przejść na szybsze przechowywanie (np. SSD na NVMe).
Krok siódmy: Zapobieganie i ciągłe monitorowanie
Nie powinieneś musieć ręcznie logować się i sprawdzać obciążenia za każdym razem. Możesz ustawić monitorowanie i alerty za pomocą narzędzi takich jak: glances, netdata, prometheus, itp.
Szybkie polecenia referencyjne
| Cel | Polecenie |
|---|---|
| Pokaż średnią obciążenia | uptime |
| Zobacz obciążenie CPU/pamięci wizualnie | htop |
| Minimalny widok procesów | top |
| Monitoruj aktywność dysku | iotop-c |
| Przeglądaj dzienniki | journalctl -xe |
Przykład z życia: Uciekający skrypt kopii zapasowej
Połączmy wszystko razem z rzeczywistym scenariuszem.
Sytuacja
- VPS z 2 rdzeniami CPU i przechowywaniem SSD
- Nagle staje się bardzo wolny – opóźnienie SSH, strony internetowe wygasają
uptimepokazuje: średnia obciążenia: 8.5, 7.3, 6.9 – zdecydowanie za wysokie dla 2 rdzeni.
Śledztwo
- Uruchom
htop: użycie CPU jest niskie – tylko 10–15%. Użycie pamięci jest w porządku. Więc nie jest to związane z CPU. - Uruchom
top: %wa = 40% – system czeka na I/O dysku. - Uruchom
iotop-c:
Bingo – skrypt kopii zapasowej kompresujący ogromny katalog bezpośrednio na dysku.
Naprawa
- Zatrzymaj lub przesuń kopię zapasową na noc.
- Kompresuj do
/tmp(w pamięci) przed przeniesieniem na dysk. - Użyj
ionice, aby zmniejszyć jego priorytet dysku.
Wynik
Wydajność VPS wraca do normy natychmiast.
Ostateczne myśli
Diagnozowanie wysokiego obciążenia to nie magia – chodzi o systematyczne sprawdzanie CPU, pamięci i dysku jeden po drugim. Używaj swoich narzędzi jak detektyw:
- Czy CPU jest maksymalnie obciążone? –
htop,top - Czy pamięć jest pełna lub swapuje? –
htop,top - Czy dysk jest przeciążony? –
iotop-c - Czy dzienniki to potwierdzają? –
journalctl
Gdy zidentyfikujesz winny proces, możesz zdecydować: dostroić go, zabić lub lepiej zaplanować. Z czasem zaczniesz rozpoznawać wzorce – proces o dużym obciążeniu, zbyt wiele zadań cron lub źle skonfigurowana aplikacja webowa. Wtedy przestaniesz gasić pożary i zaczniesz zarządzać jak prawdziwy administrator systemu.




















































