

Цілі & Результати

Контекст
У самому серці Німеччини, в жвавому технологічному центрі, знаходився сміливий стартап з баченням, яке могло змінити цифровий ландшафт. Ця інноваційна компанія, відома своїми передовими розробками в галузі штучного інтелекту, націлилася на щось по-справжньому екстраординарне. Вони хотіли створити модель мови штучного інтелекту, яка могла б конкурувати з легендарним ChatGPT, але з однією особливістю: вона повинна була працювати повністю в їхній власній мережі.
Це був не просто звичайний проєкт. Стартап вже справив фурор своїм новаторським додатком — складним чат-ботом, призначеним для імітації людського спілкування. Уявіть собі цифрового компаньйона, настільки інтуїтивного і гострого, що він зможе зрозуміти ваші питання і відповісти з тією ж нюансировкою і глибиною, що й досвідчений експерт.
Але як вони це зробили? Секрет полягав у їхньому володінні машинним навчанням. Вони розробили складні алгоритми, які дозволили їхньому ШІ вивчати мову на основі величезних обсягів даних, розпізнаючи закономірності і приймаючи рішення на льоту. На відміну від традиційного програмного забезпечення, яке необхідно програмувати для кожного можливого сценарію, їхній ШІ міг думати сам за себе, адаптуючись і розвиваючись при кожній новій взаємодії.
Додаток вже заслужив репутацію блискавично відповідаючого навіть на найскладніші запити завдяки наявності обширної бази. Ця база черпала інформацію з Інтернету і надавала користувачам точні, контекстно-орієнтовані відповіді. Якщо ви запитуєте про таємниці Всесвіту або про останні тенденції в галузі технологій, цей ШІ допоможе вам.
У міру того як стартап продовжував вдосконалювати своє творіння, стало ясно, що вони знаходяться на межі чогось революційного. Їхній інструмент штучного інтелекту не просто відповідав на питання; мова йшла про перетворення того, як люди взаємодіють з інформацією. Завдяки зручному інтерфейсу і безпрецедентній точності додаток став незамінним ресурсом для всіх, кому потрібні швидкі і надійні відповіді.
Мрія німецького стартапу була чимось більшим, ніж просто технічні досягнення - це був крок вперед у тому, як ми розуміємо і використовуємо ШІ, і, готуючись втілити своє бачення в життя, компанія вже знала, що їй потрібні надійні серверні рішення.
Завдання
Ставки були високі. У клієнта, провидця в світі штучного інтелекту, була мрія, яка вимагала не що інше, як передові технології. Їм потрібен був сервер — величезна обчислювальна потужність, — який міг би протистояти титанам світу штучного інтелекту: LLaMA від Meta, Gemini від Google і Mistral. Це не просто мовні моделі; вони є вершиною сучасного штучного інтелекту, що вимагає величезних обчислювальних потужностей для обробки і аналізу даних Інтернету з найвищою точністю.
У світі штучного інтелекту влада — це не просто розкіш, це необхідність. Клієнт знав, що для повного розкриття потенціалу цих моделей його сервер повинен бути механізмом, здатним справлятися з інтенсивними робочими навантаженнями без найменшого натяку на нестабільність. Найменший збій може обернутися катастрофою, порушити безперебійний потік інформації і призвести до неприємних затримок або, що ще гірше, до неточних результатів. Але з правильним сервером, створеним для того, щоб витримувати і перевершувати інших, клієнт зможе розкрити всю міць свого рішення штучного інтелекту, кожен раз забезпечуючи блискавичні і надійні відповіді.
Тим не менш, потреба в потужності не обмежувалася чистою продуктивністю. Клієнт також розумів, що світ штучного інтелекту постійно змінюється: нові знання і прориви з'являються невпинно. Щоб залишатися попереду, їхні рішення на базі штучного інтелекту повинні були розвиватися так само швидко, включаючи останні досягнення, щоб залишатися гострими, актуальними і дивовижно точними. Це означало регулярні оновлення і постійне прагнення до досконалості. Крім того, тільки сервер, здатний здійснювати безперервні і ефективні оновлення, може гарантувати, що ШІ залишиться на передньому краї і завжди буде готовий відповісти на наступне важливе питання.
Для цього клієнта сервер був не просто обладнанням; це був розум їхньої імперії штучного інтелекту, ключ до втілення бачення в реальність. У даному випадку наявність сервера, здатного задовольнити величезні вимоги користувачів, гарантувало клієнту не тільки можливість розширити межі можливостей ШІ, але й переосмислити майбутнє інтелектуальних технологій.

Результат
У світі ШІ, де ставки високі, швидкість вирішує все. Коли справа доходить до запуску мовної моделі штучного інтелекту, здатність блискавично обробляти інформацію може означати різницю між блиском і посередністю. Завдання величезне: просіювати дані в Інтернеті, аналізувати їх в режимі реального часу і надавати точні висновки — і все це в мить ока.
Ми знали, що для того, щоб впоратися з цим завданням, нам потрібно щось більше, ніж просто потужна система; нам потрібен був технологічний шедевр. Ось чому ми вибрали сервер, оснащений графічним процесором NVIDIA Tesla V100, чудовиськом машини, відомої своєю неперевершеною продуктивністю. Це не просто графічний процесор — це вершина лінійки NVIDIA, оснащена передовою технологією Tensor Core, яка виводить обробку ШІ на новий рівень.
Уявіть собі машину настільки потужну, що вона може з легкістю вирішувати найскладніші завдання штучного інтелекту, без особливих зусиль обробляючи дані з запаморочливою швидкістю. Tesla V100 розроблений з урахуванням вимог сучасного штучного інтелекту, що робить його ідеальним вибором для будь-якого сценарію, де швидка обробка великих обсягів даних не підлягає обговоренню. Завдяки цьому графічному процесору мовна модель штучного інтелекту стає силою, з якою потрібно рахуватися, здатною надавати результати швидше і точніше, ніж будь-коли раніше.
У руках цієї потужної машини ШІ не просто реагує — він заряджений, готовий з ловкістю вирішувати найскладніші завдання. Tesla V100 не просто відповідає вимогам штучного інтелекту; він стирає їх, встановлюючи новий стандарт того, що можливо в світі інтелектуальних технологій.
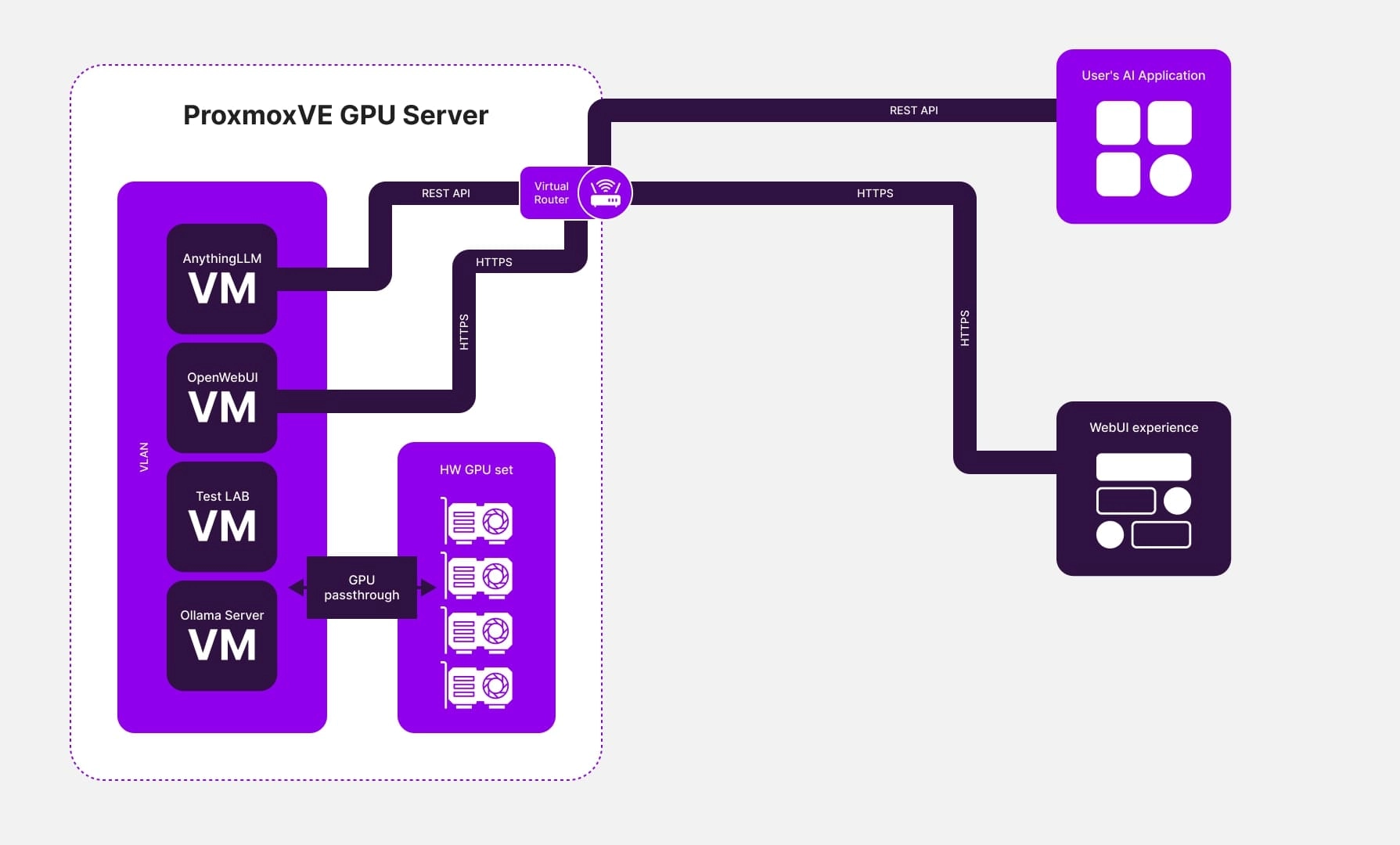
Процес вибору конфігурації сервера
Повертаючись до процесу вибору ідеальної конфігурації сервера для нашого замовника, він виглядав наступним чином:
Ретельно зібравши необхідну інформацію від замовника щодо бажаних завдань, ми надали індивідуальну конфігурацію, що відповідає конкретним вимогам і забезпечує ефективну обробку великих обсягів даних для навчання моделі ШІ.
Запропонована нами початкова конфігурація була наступною (зверніть увагу, що її можна налаштувати відповідно до уподобань клієнта):
• Процесор: 2 x Intel Xeon Gold 6248R
• Оперативна пам'ять: 512 ГБ DDR4.
• Сховище: 4 ТБ SSD NVMe.
• Відеокарти: 4 NVIDIA Tesla V100.
Перш ніж представити остаточне серверне рішення, необхідно було доопрацювати конфігурацію сервера, орієнтовану на клієнта. Для досягнення цієї мети ми ініціювали розслідування для збору інформації з наступних аспектів:
- Планований обсяг даних, що підлягають обробці і навчанню на моделі ШІ.
- Уподобання щодо конкретних графічних процесорів та інших важливих компонентів.
Отримавши додаткову інформацію від клієнта щодо обсягу даних і уподобань в обладнанні, ми запропонували остаточну конфігурацію сервера, що відповідає наступним конкретним вимогам.
- Оренда сервера. З огляду на початкові вимоги клієнта, для конфігурації потрібні були потужні процесори, великий обсяг оперативної пам'яті і кілька відеокарт.
- Використання програмного забезпечення для віртуалізації. Щоб задовольнити потреби клієнта, ми впровадили інфраструктуру на основі віртуалізації. Ця установка включала кілька віртуальних машин, кожна з яких була оснащена власними графічними адаптерами.
- Установка серверів мовних моделей. На віртуальні машини були встановлені сервери мовних моделей Ollama і OpenWebUI, а також сервер, який забезпечував доступ до зручного і безпечного веб-інтерфейсу для управління мовними моделями, наприклад AnythingLLM. AnythingLLM також пропонував доступ до API для інтеграції з іншими клієнтськими розробками.
- Запуск моделі: клієнт успішно запустив свою модель штучного інтелекту, забезпечивши стабільну роботу і високу продуктивність на сервері.

Висновок
У той момент, коли Tesla V100 був інтегрований в сервер клієнта, це було схоже на вивільнення дрімаючої електростанції. Продуктивність сервера не просто покращилася — вона злетіла до небес, зруйнувавши обмеження традиційних процесорів. Завдяки винятковим можливостям графічного процесора Tesla V100 сервер набув безпрецедентної потужності і пропускної здатності, з легкістю подолавши обмеження однопроцесорних систем.
Цей стрибок в технологіях стосувався не тільки апаратного забезпечення; мова йшла про перетворення всього проєкту ШІ клієнта. Наш інноваційний підхід до оптимізації конфігурації серверів став основою їхнього успіху. Коли мовна модель штучного інтелекту була запущена на сервері клієнта, результати виявилися просто вражаючими:
-
Неперевершена якість обслуговування
Здатність ШІ давати швидкі і точні відповіді здійснила квантовий стрибок. Користувачі стали отримувати більш швидкі і точні відповіді, а модель спритно справлялася навіть з найскладнішими запитами. Це було не просто оновлення, це була революція в задоволенні користувачів і підвищенні якості обслуговування.
-
Підвищена продуктивність
Навчання моделі ШІ стало оптимізованим і ефективним процесом завдяки величезній обчислювальній потужності, що знаходиться в її розпорядженні. Великі набори даних, які колись виснажували системи, тепер оброблялися з запаморочливою швидкістю, що скорочувало час навчання і прискорювало еволюцію моделі. Реалізація ШІ була швидшою, плавнішою і ефективнішою, ніж будь-коли раніше.
-
Безмежна масштабованість
Серверна архітектура, яку ми створили, була створена не тільки для сьогоднішнього дня, вона була спроєктована для майбутнього. Завдяки масштабованості, закладеній в його основу, клієнт міг легко розширювати свій проєкт у міру зростання бази користувачів і збільшення вимог. Така гнучкість гарантувала, що ШІ зможе розвиватися разом з амбіціями клієнта без необхідності кардинальних технічних змін.
Зрештою, це був не просто проєкт — це був тріумф. Інтегрувавши модель мови штучного інтелекту на свій сервер, клієнт отримав три переваги: значно покращене якість обслуговування, підвищена продуктивність і додана надійна масштабованість. Ці досягнення не просто виправдали очікування; вони встановлюють новий стандарт того, що можливо, коли передові технології поєднуються з далекоглядним виконанням. Майбутнє штучного інтелекту настало, і воно було яскравішим, ніж будь-коли.