

En una era en la que cada hora de inactividad se traduce en el incumplimiento de los plazos de entrega de los proyectos, y la velocidad de procesamiento de vídeo repercute directamente en la competitividad de los productos, los desarrolladores de aplicaciones multimedia no pueden confiar en arquitecturas lastradas por la sobrecarga de la virtualización en la nube, que se traduce en un rendimiento impredecible y limitaciones en la utilización de la CPU.
Un equipo de desarrollo de Alemania solicitó la configuración de un clúster K8s en servidores dedicados para su aplicación de transcodificación de vídeo, ya que sólo esta solución garantiza la plena utilización de los recursos informáticos con los máximos valores de E/S.

Objetivos
-
Rendimiento: Alcanzar la máxima velocidad de E/S y la plena utilización de la CPU mediante el acceso directo al hardware, eliminando la sobrecarga de virtualización que resulta crítica para las tareas de transcodificación que requieren un uso intensivo de la CPU.
-
Alta disponibilidad: Eliminar todos los puntos únicos de fallo tanto en el plano de control como en los nodos trabajadores, garantizando el funcionamiento continuo del clúster. El objetivo era garantizar que la consecución del máximo rendimiento de E/S y CPU no comprometiera la tolerancia a fallos.
-
Almacenamiento replicado: Implementar almacenamiento persistente distribuido con replicación para salvaguardar los archivos de vídeo críticos y los datos de las aplicaciones.
-
Previsibilidad de costes: Sustituir las facturas impredecibles de la nube por un pago de alquiler fijo y optimizado para servidores dedicados.
Resultados
-
Utilización total de la CPU: Al evitar la capa de virtualización en los nodos de trabajo, el desarrollador proporcionó a su aplicación acceso directo a los recursos informáticos para obtener el máximo rendimiento de transcodificación.
-
Tolerancia a fallos: Mediante la distribución inteligente de recursos y componentes del sistema, se eliminaron los puntos únicos de fallo hasta el nivel de host.
-
Almacenamiento distribuido: La implementación de Longhorn redujo la sobrecarga asociada a la replicación de datos y protegió contra la pérdida de archivos de vídeo o de la base de datos incluso si fallaba algún nodo.
-
Transparencia y previsibilidad de costes: Para el equipo de desarrolladores, que ofrece servicios de soporte para su producto, se simplificó el proceso de determinación del coste del trabajo y los gastos de mantenimiento de la infraestructura.
El contexto
El desarrollador estaba trabajando en el despliegue de un paquete de software para la transcodificación de vídeo con unos requisitos de rendimiento de la plataforma excepcionales. Tras varias pruebas en una plataforma en la nube convencional, los ingenieros DevOps del cliente se encontraron con una serie de limitaciones que obstaculizaban la ejecución del proyecto.
La ralentización crítica de las cargas de trabajo de la aplicación de transcodificación y de los procesos CD/CI del cliente se debía a limitaciones fundamentales de la plataforma en nube.
Bajo rendimiento de E/S y el "impuesto del hipervisor": El entorno de nube impedía que los pods utilizaran toda la velocidad de las unidades NVMe para manejar archivos de vídeo de gran tamaño. El rendimiento real de E/S estaba artificialmente restringido por los límites de la nube y la sobrecarga de la capa de virtualización. Esta capa contribuyó a una latencia inaceptable durante la carga del vídeo de origen y la descarga del contenido procesado. Además, el cliente carecía de recursos informáticos suficientes para la transcodificación paralela debido a dos factores: una parte del rendimiento de la CPU se perdía en la virtualización y, aparentemente, debido al bajo rendimiento de las CPU en los nodos informáticos del proveedor de la nube.
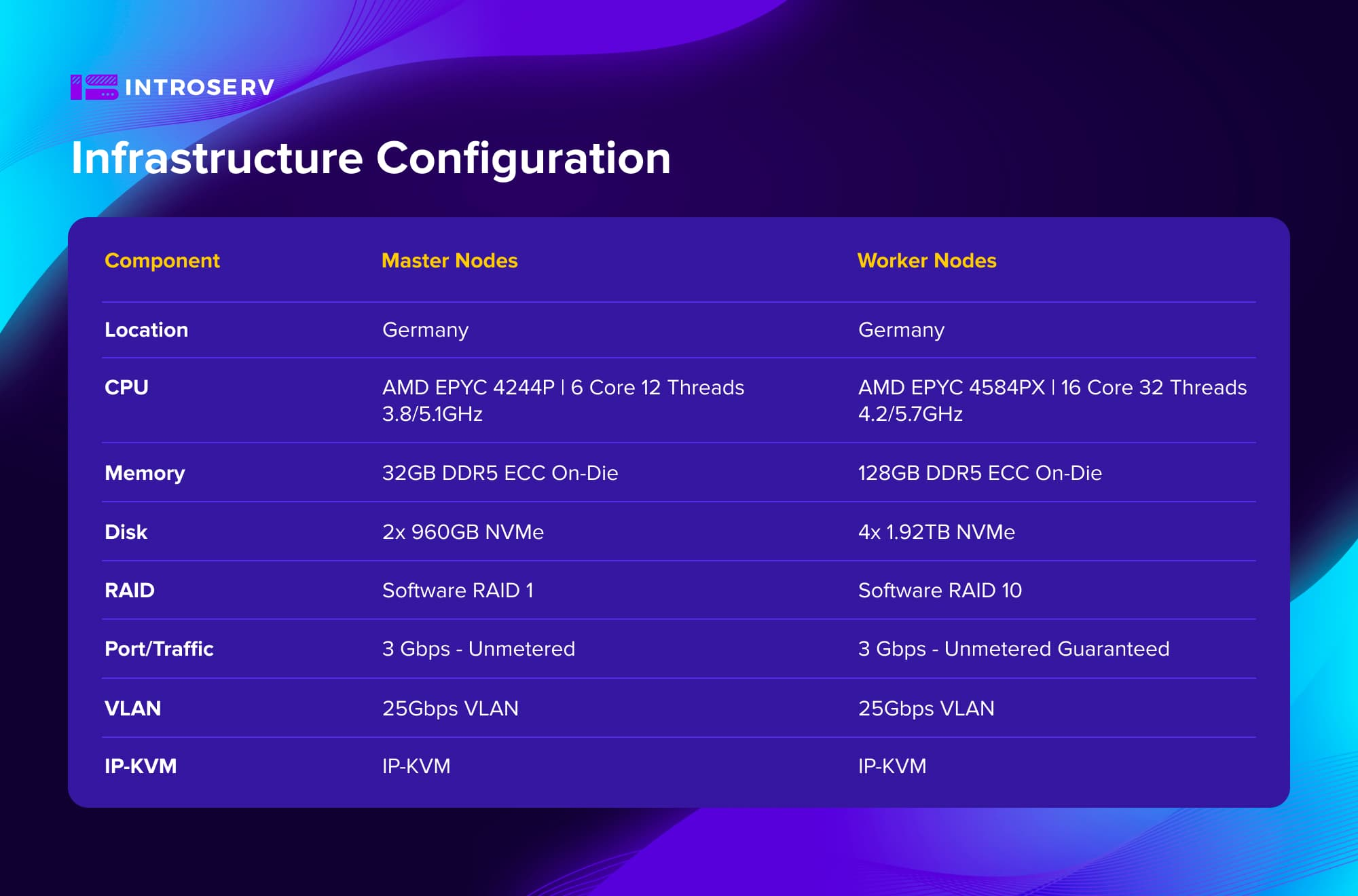
Configuración de la infraestructura
El reto
Para llevar a cabo el proyecto, era necesario abordar los siguientes retos para garantizar la personalización total, el control y el máximo rendimiento:
Seleccionar el hardware óptimo, teniendo en cuenta los elevados requisitos de velocidad de la unidad de disco para los archivos de vídeo y el rendimiento general del clúster para las tareas de transcodificación que requieren un uso intensivo de la CPU.
Configurar la red teniendo en cuenta los requisitos de disponibilidad para eliminar los puntos únicos de fallo en el plano de control y en los niveles de los trabajadores.
Implementar un clúster Kubernetes listo para producción en servidores dedicados, incorporando las mejores prácticas e implementando el almacenamiento persistente distribuido con replicación para proteger los archivos de vídeo críticos y los datos de la aplicación.
La solución
En respuesta a la solicitud de una plataforma con las máximas métricas de E/S y potencia de cálculo para la aplicación de transcodificación de vídeo, el equipo de INTROSERV desplegó un clúster Kubernetes de alto rendimiento en servidores dedicados.
Componentes clave de la solución:
Hardware optimizado: Se seleccionaron configuraciones basadas en procesadores AMD EPYC de alta frecuencia. El clúster constaba de 6 servidores dedicados: 3 nodos maestros y 3 nodos trabajadores. Esto garantizó un equilibrio óptimo entre coste y rendimiento para un entorno de alta carga con tareas de transcodificación intensivas en CPU.
Alta disponibilidad: La tolerancia a fallos se consiguió mediante una configuración de red multicapa. Se utilizaron Keepalived, HaProxy y MetalLB para eliminar los puntos únicos de fallo, garantizando el funcionamiento continuo del clúster y el equilibrio de la carga.
Almacenamiento distribuido: Se implementó el almacenamiento distribuido Longhorn con replicación para proteger los archivos de vídeo críticos y los datos de las aplicaciones. Esta solución redujo la sobrecarga asociada a la replicación de datos y proporcionó seguridad frente a la pérdida de datos, incluso en caso de fallo de cualquier nodo.
Así, INTROSERV proporcionó al cliente una plataforma que eliminaba la capa de virtualización en los nodos trabajadores, dando a los pods acceso directo al hardware, e implementó una topología tolerante a fallos de acuerdo con las mejores prácticas de la industria.
Kubernetes en Bare Metal: Máximo rendimiento sin compromiso
Gracias al nivel experto y la adaptabilidad del equipo de INTROSERV, el despliegue del clúster Kubernetes se completó con éxito, a pesar de las complejidades específicas de una solución de este tipo.
La transición a los servidores dedicados de INTROSERV permitió al equipo de desarrollo de aplicaciones multimedia alcanzar el máximo rendimiento, inalcanzable en el entorno de la nube, y obtener un control total sobre su infraestructura.
-
La plena utilización de la CPU se consiguió mediante el acceso directo a los recursos informáticos. La aplicación de transcodificación pudo utilizar los 32 subprocesos de los procesadores AMD EPYC en cada nodo trabajador sin sobrecarga de virtualización. El tiempo de procesamiento de las tareas típicas de transcodificación se redujo entre 4 y 5 veces en comparación con el entorno de nube.
-
Se eliminaron los puntos únicos de fallo a nivel de host, y se garantizó una protección fiable de los archivos de vídeo y los datos de las aplicaciones gracias al almacenamiento distribuido Longhorn con triple replicación.
-
El cliente pasó de facturas impredecibles en la nube a un pago fijo y optimizado por el alquiler de servidores físicos.
Para seleccionar la infraestructura óptima para su proyecto, póngase en contacto con el departamento de ventas de INTROSERV.
































































