

In einer Zeit, in der jede Stunde Ausfallzeit zu verpassten Projektterminen führt und sich die Geschwindigkeit der Videoverarbeitung direkt auf die Wettbewerbsfähigkeit von Produkten auswirkt, können sich die Entwickler von Medienanwendungen nicht auf Architekturen verlassen, die durch den Overhead der Cloud-Virtualisierung belastet werden, was zu unvorhersehbarer Leistung und Einschränkungen bei der CPU-Auslastung führt.
Ein Entwicklungsteam aus Deutschland beantragte die Konfiguration eines K8s-Clusters auf dedizierten Servern für seine Videotranskodierungsanwendung, da nur diese Lösung die volle Nutzung der Rechenressourcen mit maximalen E/A-Werten gewährleistet.

Ziele
-
Leistung: Maximale E/A-Geschwindigkeit und volle CPU-Auslastung durch direkten Hardware-Zugriff, wodurch der Virtualisierungs-Overhead entfällt, der für CPU-intensive Transcodierungsaufgaben entscheidend ist.
-
Hohe Verfügbarkeit: Eliminierung aller Single Points of Failure sowohl auf der Steuerungsebene als auch auf der Ebene der Arbeitsknoten, um einen kontinuierlichen Betrieb des Clusters zu gewährleisten. Das Ziel war es, sicherzustellen, dass die maximale E/A- und CPU-Leistung nicht die Fehlertoleranz beeinträchtigt.
-
Replizierte Speicherung: Implementierung eines verteilten persistenten Speichers mit Replikation zur Sicherung wichtiger Videodateien und Anwendungsdaten.
-
Kostenvorhersagbarkeit: Ersetzen Sie unvorhersehbare Cloud-Rechnungen durch eine feste, optimierte Leasingzahlung für dedizierte Server.
Ergebnisse
-
Volle CPU-Auslastung: Durch Umgehung der Virtualisierungsschicht auf den Worker Nodes konnte der Entwickler seiner Anwendung direkten Zugriff auf die Rechenressourcen gewähren und so eine maximale Transcodierungsleistung erzielen.
-
Fehlertoleranz: Durch die intelligente Verteilung von Ressourcen und Systemkomponenten wurden einzelne Fehlerquellen bis hinunter auf die Host-Ebene eliminiert.
-
Verteilter Speicher: Die Implementierung von Longhorn reduzierte den mit der Datenreplikation verbundenen Overhead und schützte vor dem Verlust von Videodateien oder der Datenbank, selbst wenn ein Knoten ausfällt.
-
Transparenz und Kostenvorhersagbarkeit: Für das Entwicklerteam, das Supportdienste für sein Produkt anbietet, wurde der Prozess der Ermittlung der Kosten für Arbeit und Infrastrukturwartung vereinfacht.
Der Kontext
Der Entwickler arbeitete an der Bereitstellung einer Software-Suite für die Videotranscodierung mit außergewöhnlichen Leistungsanforderungen an die Plattform. Nach mehreren Tests auf einer herkömmlichen Cloud-Plattform stießen die DevOps-Ingenieure des Kunden auf eine Reihe von Einschränkungen, die die Projektumsetzung behinderten.
Die kritische Verlangsamung der Arbeitslasten der Transcodierungsanwendung und der CD/CI-Prozesse des Kunden wurde durch grundlegende Einschränkungen der Cloud-Plattform verursacht.
Geringe E/A-Leistung und die "Hypervisor-Steuer": Die Cloud-Umgebung hinderte die Pods daran, die volle Geschwindigkeit der NVMe-Laufwerke für die Verarbeitung großer Videodateien zu nutzen. Die tatsächliche E/A-Leistung wurde durch Cloud-Grenzen und den Overhead der Virtualisierungsschicht künstlich eingeschränkt. Diese Schicht trug zu inakzeptablen Latenzzeiten beim Hochladen von Quellvideos und beim Herunterladen von verarbeiteten Inhalten bei. Darüber hinaus verfügte der Client nicht über ausreichende Rechenressourcen für die parallele Transkodierung, was auf zwei Faktoren zurückzuführen war: Ein Teil der CPU-Leistung ging durch die Virtualisierung verloren, und die CPUs auf den Rechenknoten des Cloud-Anbieters waren offenbar nicht ausreichend leistungsfähig.
Konfiguration der Infrastruktur
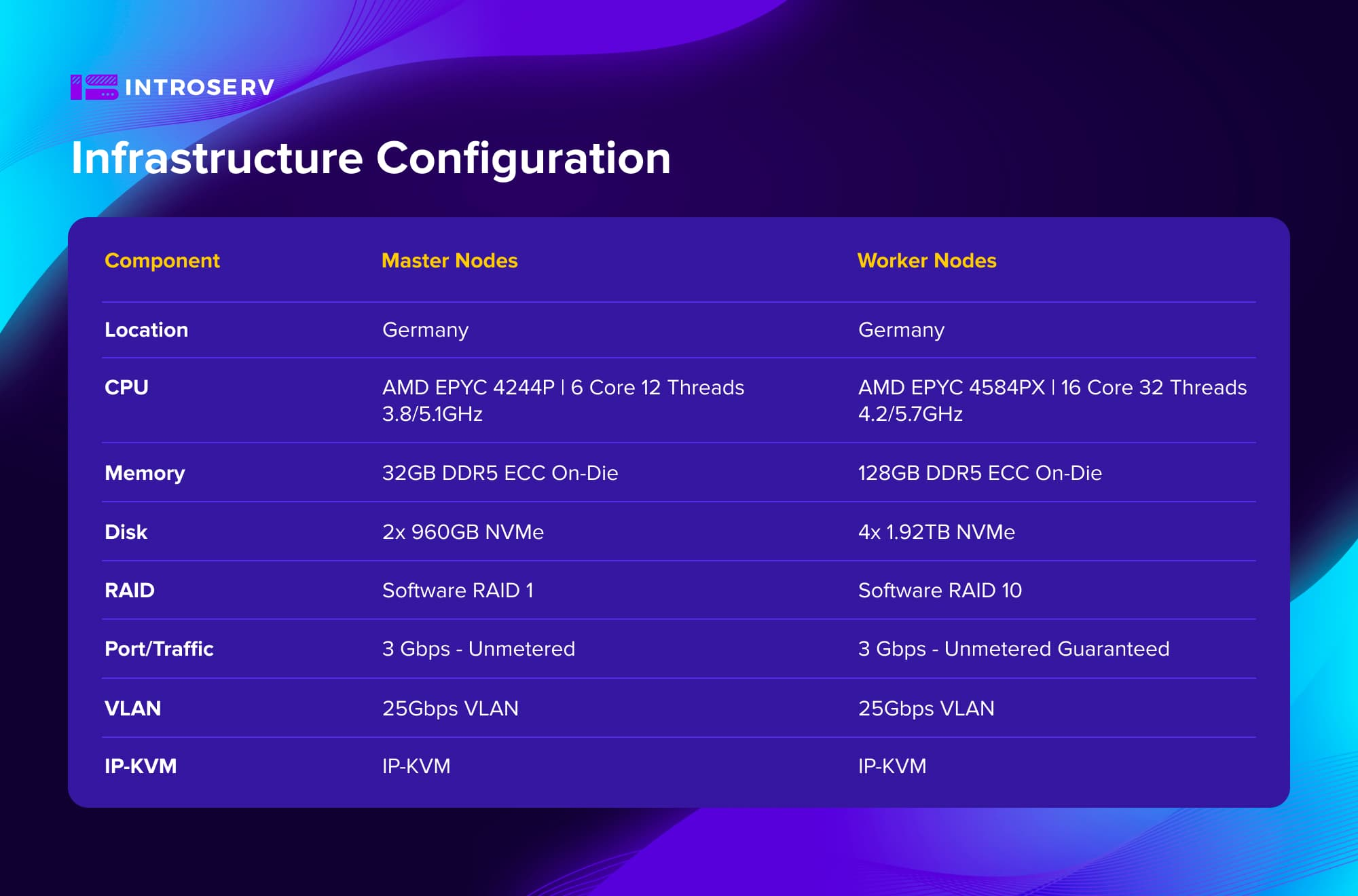
Die Herausforderung
Um das Projekt zu realisieren, mussten die folgenden Herausforderungen bewältigt werden, um eine vollständige Anpassung, Kontrolle und maximale Leistung zu gewährleisten:
Auswahl der optimalen Hardware unter Berücksichtigung der hohen Anforderungen an die Laufwerksgeschwindigkeit für Videodateien und die Gesamtleistung des Clusters für CPU-intensive Transcodierungsaufgaben.
Konfigurieren Sie das Netzwerk unter Berücksichtigung von Hochverfügbarkeitsanforderungen , um einzelne Ausfallpunkte auf der Steuerungsebene und den Worker-Ebenen zu vermeiden.
Bereitstellung eines produktionsbereiten Kubernetes-Clusters auf dedizierten Servern unter Berücksichtigung bewährter Verfahren und Implementierung eines verteilten persistenten Speichers mit Replikation zum Schutz wichtiger Videodateien und Anwendungsdaten.
Die Lösung
Als Antwort auf die Anforderung nach einer Plattform mit maximalen E/A-Metriken und Rechenleistung für die Videotranskodierungsanwendung stellte das INTROSERV-Team einen hochleistungsfähigen Kubernetes-Cluster auf dedizierten Servern bereit.
Schlüsselkomponenten der Lösung:
Optimierte Hardware: Es wurden Konfigurationen auf Basis von hochfrequenten AMD EPYC-Prozessoren gewählt. Der Cluster bestand aus 6 dedizierten Servern - 3 Master-Knoten und 3 Worker-Knoten. Dadurch wurde ein optimales Gleichgewicht zwischen Kosten und Leistung für eine Hochlastumgebung mit CPU-intensiven Transcodierungsaufgaben gewährleistet.
Hohe Verfügbarkeit: Die Fehlertoleranz wurde durch eine mehrschichtige Netzwerkkonfiguration erreicht. Keepalived, HaProxy und MetalLB wurden eingesetzt, um einzelne Ausfallpunkte zu eliminieren und einen kontinuierlichen Clusterbetrieb und Lastausgleich zu gewährleisten.
Verteilter Speicher: Longhorn Distributed Storage mit Replikation wurde implementiert, um kritische Videodateien und Anwendungsdaten zu schützen. Diese Lösung reduzierte den mit der Datenreplikation verbundenen Overhead und bot Sicherheit vor Datenverlusten, selbst im Falle des Ausfalls eines Knotens.
INTROSERV stellte dem Kunden eine Plattform zur Verfügung, die die Virtualisierungsschicht auf den Worker Nodes eliminierte, den Pods direkten Zugriff auf die Hardware ermöglichte und eine fehlertolerante Topologie in Übereinstimmung mit den Best Practices der Branche implementierte.
Kubernetes auf Bare Metal: Maximale Leistung ohne Kompromisse
Dank der Kompetenz und Anpassungsfähigkeit des INTROSERV-Teams konnte die Implementierung des Kubernetes-Clusters trotz der spezifischen Komplexität einer solchen Lösung erfolgreich abgeschlossen werden.
Die Umstellung auf dedizierte INTROSERV-Server ermöglichte es dem Entwicklungsteam der Medienanwendung, eine in der Cloud-Umgebung unerreichte maximale Performance zu erreichen und die volle Kontrolle über ihre Infrastruktur zu erhalten.
-
Die volle CPU-Auslastung wurde durch den direkten Zugriff auf die Rechenressourcen erreicht. Die Transcodierungsanwendung konnte alle 32 Threads der AMD EPYC-Prozessoren auf jedem Worker-Knoten ohne Virtualisierungs-Overhead nutzen. Die Verarbeitungszeit für typische Transcodierungsaufgaben wurde im Vergleich zur Cloud-Umgebung um das 4-5-fache reduziert.
-
Einzelne Fehlerquellen wurden auf Host-Ebene eliminiert und ein zuverlässiger Schutz von Videodateien und Anwendungsdaten wurde dank Longhorn Distributed Storage mit dreifacher Replikation gewährleistet.
-
Der Kunde wechselte von unvorhersehbaren Cloud-Rechnungen zu einer festen, optimierten Leasingzahlung für physische Server.
Um die optimale Infrastruktur für Ihr Projekt auszuwählen, wenden Sie sich bitte an den INTROSERV-Vertrieb.
































































