

В епоху, коли кожна година простою означає зрив дедлайнів проекту, а швидкість обробки відео безпосередньо впливає на конкурентоспроможність продукту, розробники медіа-застосунків не можуть покладатися на архітектури з витратами хмарної віртуалізації у вигляді непередбачуваної продуктивності та обмежень в утилізації CPU.
Команда розробників з Німеччини звернулася із запитом налаштування k8s кластера на базі виділених серверів для розроблюваного застосунку транскодування відео, оскільки лише таке рішення дозволяє забезпечити повну утилізацію обчислювальних ресурсів з максимальними значеннями I/O.

Цілі
Продуктивність: Досягти максимальної швидкості I/O та повної утилізації CPU за рахунок прямого доступу до обладнання, виключивши накладні витрати віртуалізації, які є критичними для CPU-інтенсивних завдань транскодування.
Висока Доступність: Усунути всі єдині точки відмови на адміністративному та обчислювальному рівнях, забезпечивши безперервність роботи кластера, адже максимальний I/O та продуктивність CPU не повинні були призвести до втрати відмовостійкості.
Репліковане Сховище: Впровадити розподілене постійне сховище з реплікацією для захисту критично важливих відеофайлів та даних застосунку.
Прогнозованість Витрат: Замінити непередбачувані хмарні рахунки на фіксовану, оптимізовану орендну плату за виділені сервери.
Результати
Прозорість та передбачуваність вартості послуг: Для команди розробника, яка надає послуги підтримки свого продукту, спрощено процедуру визначення собівартості робіт та частини витрат на утримання інфраструктури.
Повна утилізація CPU: Відмовившись від шару віртуалізації на worker-нодах, розробник надав своєму застосунку прямий доступ до обчислювальних ресурсів для максимальної продуктивності транскодування.
Відмовостійкість: Завдяки грамотному розподілу ресурсів та компонентів системи вдалося виключити єдині точки відмови аж до рівня хоста.
Розподілене сховище: Використання Longhorn дозволило знизити витрати, викликані реплікацією даних, та убезпечило від втрати відеофайлів чи БД навіть у разі виходу з ладу будь-якої з нод.
Контекст
Розробник працював над впровадженням програмного комплексу для транскодування відео з винятковими вимогами до продуктивності платформи. Після низки тестів на звичній хмарній платформі DevOps інженери замовника зіткнулися з низкою обмежень, які заважали реалізації проекту.
Критичне уповільнення робочих навантажень застосунку транскодування та CD/CI процесів клієнта було викликане фундаментальними обмеженнями хмарної платформи.
Низька I/O-Продуктивність та "Податок" Гіпервізора:
Хмарне середовище не дозволяло подам використовувати повну швидкість накопичувачів NVMe для роботи з великими відеофайлами. Реальна продуктивність введення/виведення штучно обмежувалася хмарними лімітами та накладними витратами шару віртуалізації. Цей шар сприяв неприйнятним затримкам при завантаженні вихідного відео та вивантаженні обробленого контенту. Крім цього, клієнту не вистачало обчислювальних ресурсів для паралельного транскодування через два фактори: частина продуктивності CPU втрачалася через віртуалізацію, і, судячи з усього, через малопродуктивні ЦПУ на обчислювальних нодах хмарного провайдера.
Задача
Для реалізації проекту вимагалося вирішити наступні завдання, щоб забезпечити повну кастомізацію, контроль та максимальну продуктивність:
Підібрати оптимальне апаратне забезпечення з урахуванням високих вимог до швидкості накопичувачів для роботи з відеофайлами та загальної продуктивності кластера для CPU-intensive завдань транскодування.
Налаштувати мережу з урахуванням вимог високої доступності, щоб виключити єдині точки відмови на адміністративному та обчислювальному рівнях.
Розгорнути готовий Kubernetes кластер на базі виділених серверів, враховуючи найкращі практики та впровадивши розподілене постійне сховище з реплікацією для захисту критично важливих відеофайлів та даних застосунку.
Конфігурація інфраструктури
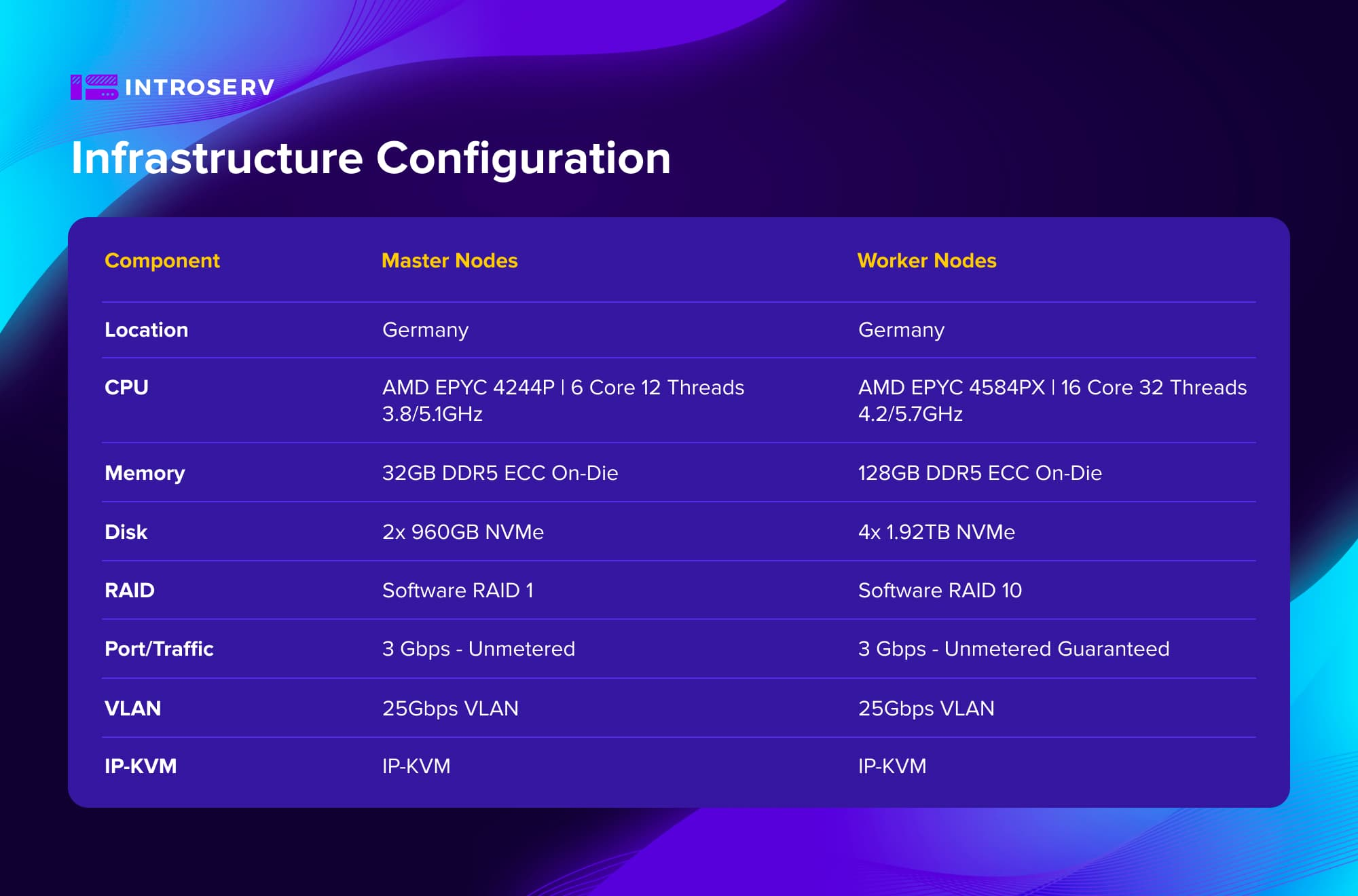
Виклик
Для реалізації проекту необхідно було вирішити наступні завдання, щоб забезпечити повну кастомізацію, контроль та максимальну продуктивність:
Підібратиоптимальне апаратне забезпечення, враховуючи високі вимоги до швидкості накопичувачів для відеофайлів та загальної продуктивності кластера для ресурсоємних завдань транскодування.
Налаштуйте мережу з урахуванням вимогдо високої доступності , щоб усунути єдині точки відмови на рівні управління та на робочому рівні.
Розгорнути готовий до виробництва кластер Kubernetes на виділених серверах, використовуючи найкращі практики та впроваджуючи розподілене постійне сховище з реплікацією для захисту критично важливих відеофайлів та даних додатків.
Рішення
У відповідь на запит щодо створення платформи з максимальними показниками I/O та обчислювальною потужністю для застосунку транскодування відео, команда INTROSERV розгорнула високопродуктивний Kubernetes-кластер на виділених серверах.
Ключові компоненти рішення:
Оптимізоване апаратне забезпечення: Були підібрані конфігурації на базі високочастотних процесорів AMD EPYC. Кластер складався з 6 виділених серверів – 3 master-ноди та 3 worker-ноди. Це забезпечило оптимальний баланс між вартістю та продуктивністю для високонавантаженого середовища із CPU-intensive завданнями транскодування.
Висока доступність: Відмовостійкість була досягнута за рахунок багаторівневого налаштування мережі. Були використані Keepalived, HaProxy та MetalLB для усунення єдиних точок відмови, гарантуючи безперервність роботи кластера та балансування навантаження.
Розподілене сховище: Для захисту критично важливих відеофайлів та даних застосунку було впроваджено розподілене сховище Longhorn з реплікацією. Це рішення дозволило знизити витрати, пов'язані з реплікацією даних, та забезпечило безпеку від їхньої втрати навіть у разі виходу з ладу будь-якої ноди.
Таким чином, INTROSERV надав замовнику платформу, яка виключила шар віртуалізації на worker-нодах, надавши подам прямий доступ до обладнання, а також впровадив відмовостійку топологію відповідно до найкращих практик.
Kubernetes на фізичних серверах: Максимальна продуктивність без компромісів
Завдяки експертному рівню та адаптивності команди INTROSERV, розгортання Kubernetes Cluster було виконано успішно, незважаючи на специфічні складнощі подібного рішення.
Перехід на виділені сервери INTROSERV дозволив команді розробників медіа-застосунку досягти максимальної продуктивності, недосяжної у хмарному середовищі, та повністю контролювати свою інфраструктуру.
Досягнуто повної утилізації CPU завдяки прямому доступу до обчислювальних ресурсів. Застосунок транскодування отримав можливість використовувати всі 32 потоки процесорів AMD EPYC на кожній worker-ноді без накладних витрат віртуалізації. Час обробки типових завдань транскодування скоротився у 4-5 разів у порівнянні з хмарним середовищем.
Виключені єдині точки відмови на рівні хоста та забезпечений надійний захист відеофайлів і даних застосунків завдяки розподіленому сховищу Longhorn із потрійною реплікацією.
Замовник перейшов від непередбачуваних хмарних рахунків до фіксованої, оптимізованої орендної плати за фізичні сервери.
Для підбору оптимальної інфраструктури під ваш проект зв'яжіться з відділом продажу INTROSERV.
































































