

W czasach, w których każda godzina przestoju przekłada się na niedotrzymanie terminów projektów, a szybkość przetwarzania wideo ma bezpośredni wpływ na konkurencyjność produktu, twórcy aplikacji multimedialnych nie mogą polegać na architekturach obciążonych narzutem wirtualizacji w chmurze, co skutkuje nieprzewidywalną wydajnością i ograniczeniami w wykorzystaniu procesora.
Zespół programistów z Niemiec poprosił o skonfigurowanie klastra K8s na dedykowanych serwerach dla swojej aplikacji do transkodowania wideo, ponieważ tylko to rozwiązanie zapewnia pełne wykorzystanie zasobów obliczeniowych przy maksymalnych wartościach we/wy.

Cele
-
Wydajność: Osiągnięcie maksymalnej prędkości I/O i pełnego wykorzystania CPU poprzez bezpośredni dostęp sprzętowy, eliminując narzut wirtualizacji, który jest krytyczny dla zadań transkodowania intensywnie wykorzystujących CPU.
-
Wysoka dostępność: Wyeliminowanie wszystkich pojedynczych punktów awarii zarówno na poziomie płaszczyzny sterowania, jak i węzłów roboczych, zapewniając ciągłość działania klastra. Celem było zapewnienie, że osiągnięcie maksymalnej wydajności we/wy i procesora nie wpłynie negatywnie na odporność na awarie.
-
Replikowana pamięć masowa: Wdrożenie rozproszonej trwałej pamięci masowej z replikacją w celu ochrony krytycznych plików wideo i danych aplikacji.
-
Przewidywalność kosztów: Zastąpienie nieprzewidywalnych rachunków za chmurę stałą, zoptymalizowaną opłatą za dzierżawę serwerów dedykowanych.
Wyniki
-
Pełne wykorzystanie procesora: Pomijając warstwę wirtualizacji na węzłach roboczych, deweloper zapewnił swojej aplikacji bezpośredni dostęp do zasobów obliczeniowych w celu uzyskania maksymalnej wydajności transkodowania.
-
Odporność na błędy: Dzięki inteligentnej dystrybucji zasobów i komponentów systemu, pojedyncze punkty awarii zostały wyeliminowane aż do poziomu hosta.
-
Rozproszona pamięć masowa: Wdrożenie Longhorn zmniejszyło narzut związany z replikacją danych i zabezpieczyło przed utratą plików wideo lub bazy danych nawet w przypadku awarii dowolnego węzła.
-
Przejrzystość i przewidywalność kosztów: Dla zespołu deweloperów, który świadczy usługi wsparcia dla swojego produktu, uproszczono proces określania kosztów pracy i wydatków na utrzymanie infrastruktury.
Kontekst
Deweloper pracował nad wdrożeniem pakietu oprogramowania do transkodowania wideo z wyjątkowymi wymaganiami dotyczącymi wydajności platformy. Po kilku testach na konwencjonalnej platformie chmurowej, inżynierowie DevOps klienta napotkali zestaw ograniczeń, które utrudniały realizację projektu.
Krytyczne spowolnienie obciążeń aplikacji transkodującej i procesów CD/CI klienta było spowodowane fundamentalnymi ograniczeniami platformy chmurowej.
Niska wydajność we/wy i "podatek hiperwizora": Środowisko chmury uniemożliwiało wykorzystanie pełnej prędkości dysków NVMe do obsługi dużych plików wideo. Rzeczywista wydajność we/wy była sztucznie ograniczana przez limity chmury i narzut warstwy wirtualizacji. Warstwa ta przyczyniała się do niedopuszczalnych opóźnień podczas przesyłania źródłowego materiału wideo i pobierania przetworzonej zawartości. Co więcej, klientowi brakowało wystarczających zasobów obliczeniowych do równoległego transkodowania z powodu dwóch czynników: część wydajności procesora została utracona na rzecz wirtualizacji oraz, najwyraźniej, z powodu słabych procesorów w węzłach obliczeniowych dostawcy chmury.
Konfiguracja infrastruktury
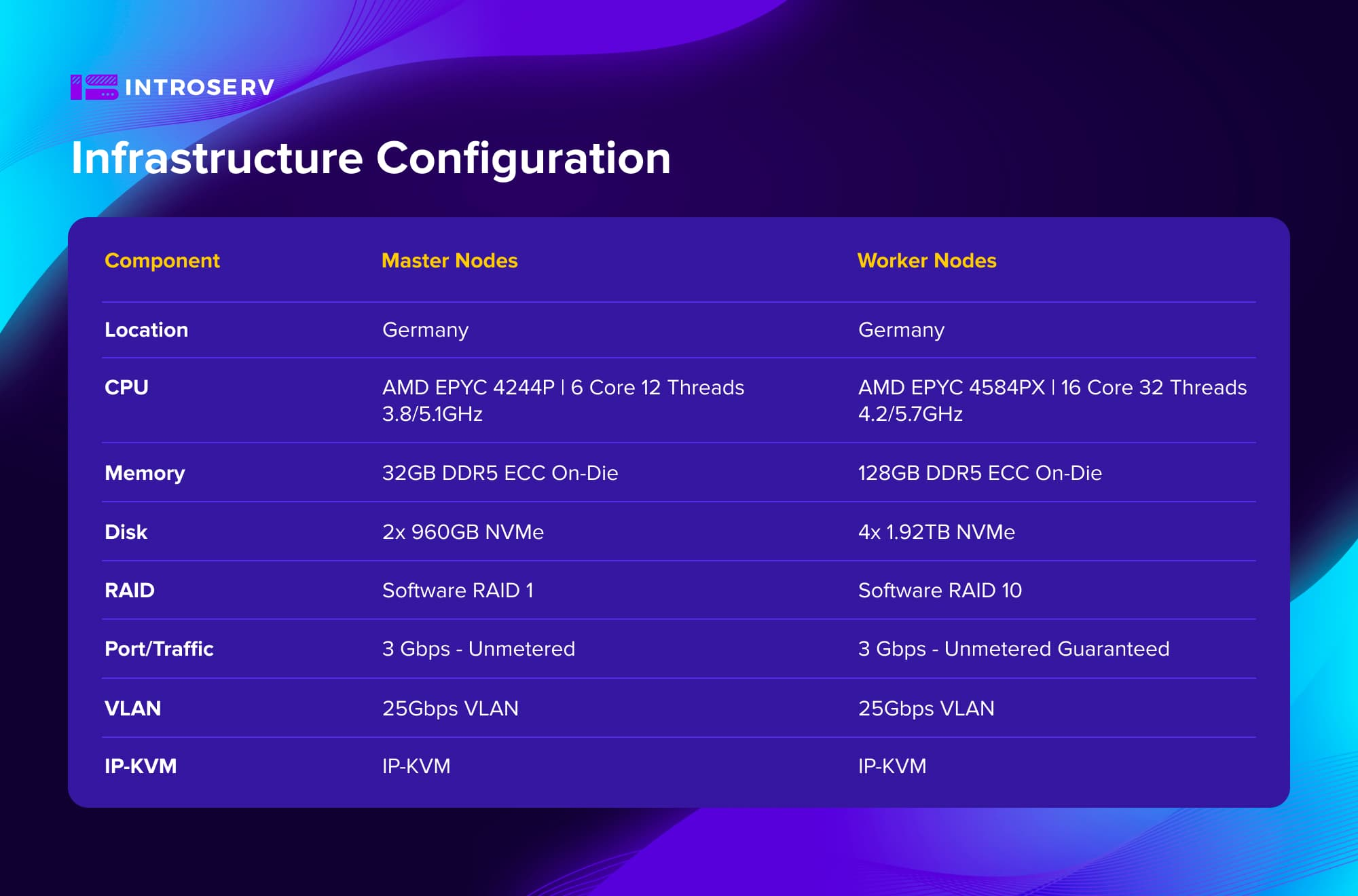
Wyzwanie
Aby zrealizować projekt, należało sprostać następującym wyzwaniom w celu zapewnienia pełnej personalizacji, kontroli i maksymalnej wydajności:
Wybór optymalnego sprzętu, biorąc pod uwagę wysokie wymagania dotyczące szybkości dysków dla plików wideo i ogólnej wydajności klastra dla zadań transkodowania wymagających dużej mocy obliczeniowej procesora.
Konfiguracja sieci z uwzględnieniem wymagań wysokiej dostępności w celu wyeliminowania pojedynczych punktów awarii na poziomie płaszczyzny sterowania i pracowników.
Wdrożenie gotowego do produkcji klastra Kubernetes na dedykowanych serwerach, z wykorzystaniem najlepszych praktyk i wdrożeniem rozproszonej trwałej pamięci masowej z replikacją w celu ochrony krytycznych plików wideo i danych aplikacji.
Rozwiązanie
W odpowiedzi na zapotrzebowanie na platformę z maksymalnymi wskaźnikami I/O i mocą obliczeniową dla aplikacji transkodowania wideo, zespół INTROSERV wdrożył wysokowydajny klaster Kubernetes na dedykowanych serwerach.
Kluczowe elementy rozwiązania:
Zoptymalizowany sprzęt: Wybrano konfiguracje oparte na procesorach AMD EPYC o wysokiej częstotliwości. Klaster składał się z 6 dedykowanych serwerów - 3 węzłów głównych i 3 węzłów roboczych. Zapewniło to optymalną równowagę między kosztami i wydajnością dla środowiska o dużym obciążeniu z zadaniami transkodowania wymagającymi dużej mocy obliczeniowej.
Wysoka dostępność: Odporność na awarie została osiągnięta dzięki wielowarstwowej konfiguracji sieci. Keepalived, HaProxy i MetalLB zostały wykorzystane do wyeliminowania pojedynczych punktów awarii, gwarantując ciągłą pracę klastra i równoważenie obciążenia.
Rozproszona pamięć masowa: Rozproszona pamięć masowa Longhorn z replikacją została wdrożona w celu ochrony krytycznych plików wideo i danych aplikacji. Rozwiązanie to zmniejszyło narzut związany z replikacją danych i zapewniło bezpieczeństwo przed utratą danych, nawet w przypadku awarii węzła.
W ten sposób INTROSERV dostarczył klientowi platformę, która wyeliminowała warstwę wirtualizacji na węzłach roboczych, dając podom bezpośredni dostęp do sprzętu i wdrożyła topologię odporną na awarie zgodnie z najlepszymi praktykami branżowymi.
Kubernetes on Bare Metal: Maksymalna wydajność bez kompromisów
Dzięki doświadczeniu i zdolnościom adaptacyjnym zespołu INTROSERV, wdrożenie klastra Kubernetes zakończyło się sukcesem, pomimo specyficznej złożoności takiego rozwiązania.
Przejście na serwery dedykowane INTROSERV pozwoliło zespołowi ds. rozwoju aplikacji medialnych osiągnąć maksymalną wydajność, nieosiągalną w środowisku chmury, i uzyskać pełną kontrolę nad swoją infrastrukturą.
-
Pełne wykorzystanie CPU zostało osiągnięte dzięki bezpośredniemu dostępowi do zasobów obliczeniowych. Aplikacja transkodująca była w stanie wykorzystać wszystkie 32 wątki procesorów AMD EPYC na każdym węźle roboczym bez narzutu wirtualizacji. Czas przetwarzania typowych zadań transkodowania został skrócony o 4-5 razy w porównaniu do środowiska chmury.
-
Pojedyncze punkty awarii zostały wyeliminowane na poziomie hosta, a niezawodna ochrona plików wideo i danych aplikacji została zapewniona dzięki rozproszonej pamięci masowej Longhorn z potrójną replikacją.
-
Klient przeszedł z nieprzewidywalnych rachunków za chmurę na stałą, zoptymalizowaną opłatę za dzierżawę serwerów fizycznych.
Aby wybrać optymalną infrastrukturę dla swojego projektu, prosimy o kontakt z działem sprzedaży INTROSERV.
































































