

In un'epoca in cui ogni ora di inattività si traduce in scadenze di progetto non rispettate e la velocità di elaborazione video ha un impatto diretto sulla competitività dei prodotti, gli sviluppatori di applicazioni multimediali non possono affidarsi ad architetture appesantite dall'overhead della virtualizzazione cloud, che comporta prestazioni imprevedibili e limitazioni nell'utilizzo della CPU.
Un team di sviluppo tedesco ha richiesto la configurazione di un cluster K8s su server dedicati per la propria applicazione di transcodifica video, poiché solo questa soluzione garantisce il pieno utilizzo delle risorse di calcolo con valori di I/O massimi.

Obiettivi
-
Prestazioni: Ottenere la massima velocità di I/O e il pieno utilizzo della CPU attraverso l'accesso diretto all'hardware, eliminando l'overhead della virtualizzazione che è fondamentale per le attività di transcodifica ad alta intensità di CPU.
-
Alta disponibilità: Eliminare tutti i singoli punti di guasto sia a livello di piano di controllo che di nodo worker, garantendo il funzionamento continuo del cluster. L'obiettivo era garantire che il raggiungimento delle massime prestazioni di I/O e CPU non compromettesse la tolleranza ai guasti.
-
Storage replicato: Implementazione di uno storage persistente distribuito con replica per salvaguardare i file video e i dati applicativi critici.
-
Prevedibilità dei costi: Sostituire le fatture imprevedibili del cloud con un canone di locazione fisso e ottimizzato per i server dedicati.
Risultati
-
Utilizzo completo della CPU: Bypassando il livello di virtualizzazione sui nodi worker, lo sviluppatore ha fornito alla sua applicazione l'accesso diretto alle risorse di calcolo per ottenere le massime prestazioni di transcodifica.
-
Tolleranza ai guasti: Grazie a una distribuzione intelligente delle risorse e dei componenti di sistema, sono stati eliminati i singoli punti di guasto fino al livello dell'host.
-
Storage distribuito: L'implementazione di Longhorn ha ridotto l'overhead associato alla replica dei dati e ha protetto dalla perdita dei file video o del database anche in caso di guasto di un nodo.
-
Trasparenza e prevedibilità dei costi: Per il team di sviluppatori, che fornisce servizi di supporto per il prodotto, è stato semplificato il processo di determinazione del costo del lavoro e delle spese di manutenzione dell'infrastruttura.
Il contesto
Lo sviluppatore stava lavorando alla distribuzione di una suite di software per la transcodifica video con requisiti eccezionali di prestazioni della piattaforma. Dopo diversi test su una piattaforma cloud convenzionale, gli ingegneri DevOps del cliente hanno riscontrato una serie di limitazioni che hanno ostacolato l'implementazione del progetto.
Il rallentamento critico dei carichi di lavoro dell'applicazione di transcodifica e dei processi CD/CI del cliente era causato da limitazioni fondamentali della piattaforma cloud.
Basse prestazioni di I/O e la "tassa sull'hypervisor": L'ambiente cloud impediva ai pod di utilizzare la piena velocità delle unità NVMe per gestire file video di grandi dimensioni. Le prestazioni di I/O effettive erano artificialmente limitate dai limiti del cloud e dall'overhead del livello di virtualizzazione. Questo livello ha contribuito a creare una latenza inaccettabile durante il caricamento dei video di origine e il download dei contenuti elaborati. Inoltre, il client non disponeva di risorse di calcolo sufficienti per la transcodifica parallela a causa di due fattori: una parte delle prestazioni della CPU è stata persa a causa della virtualizzazione e, apparentemente, a causa di CPU poco performanti sui nodi di calcolo del cloud provider.
Configurazione dell'infrastruttura
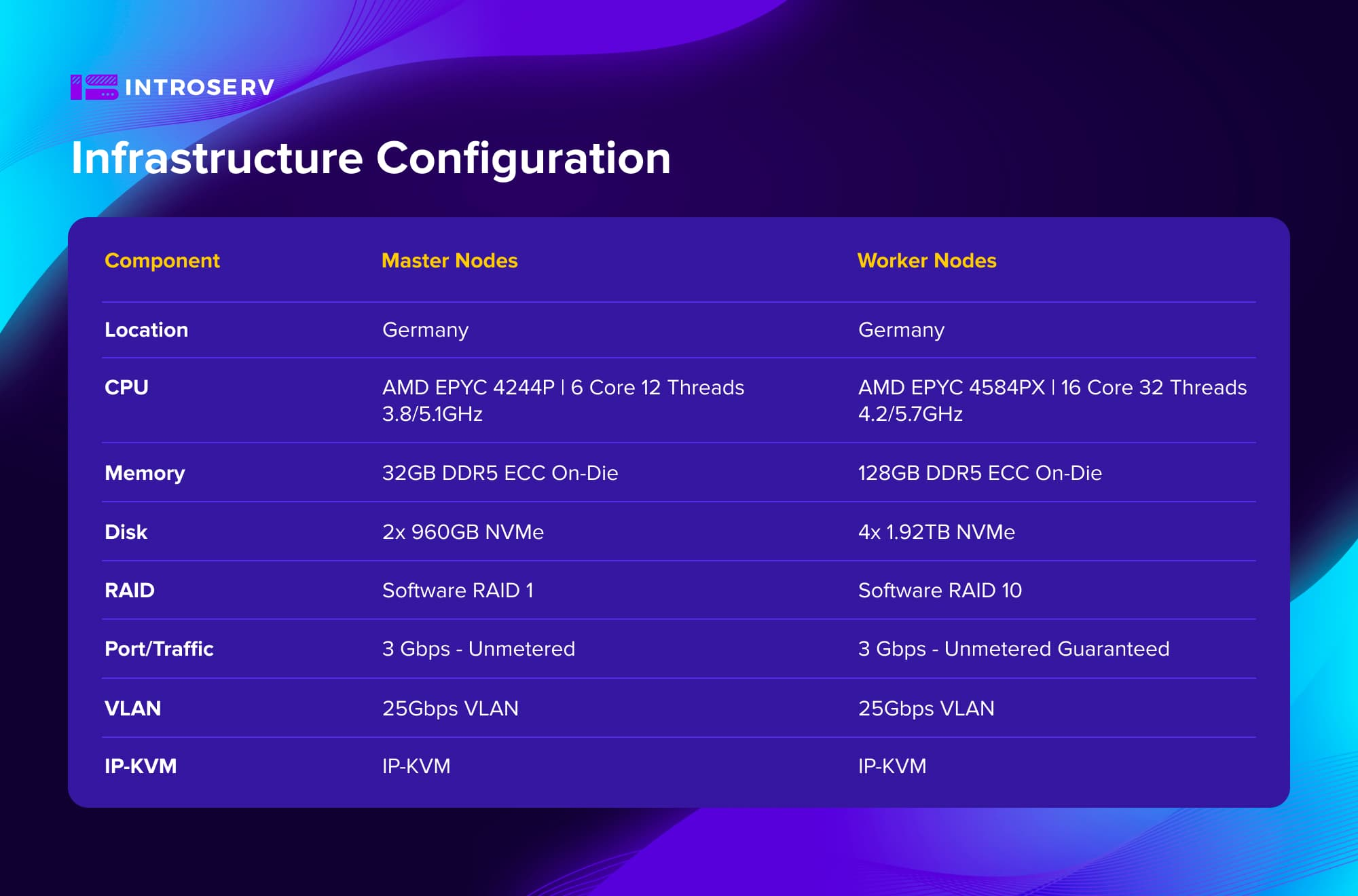
La sfida
Per realizzare il progetto, è stato necessario affrontare le seguenti sfide per garantire la piena personalizzazione, il controllo e le massime prestazioni:
Selezionare l'hardware ottimale, considerando gli elevati requisiti di velocità dell'unità per i file video e le prestazioni complessive del cluster per le attività di transcodifica ad alta intensità di CPU.
Configurare la rete tenendo conto dei requisiti di disponibilità per eliminare i singoli punti di guasto a livello del piano di controllo e dei lavoratori.
Implementare un cluster Kubernetes pronto per la produzione su server dedicati, incorporando le migliori pratiche e implementando uno storage persistente distribuito con replica per proteggere i file video e i dati applicativi critici.
La soluzione
In risposta alla richiesta di una piattaforma con metriche di I/O e potenza di calcolo massime per l'applicazione di transcodifica video, il team di INTROSERV ha implementato un cluster Kubernetes ad alte prestazioni su server dedicati.
Componenti chiave della soluzione:
Hardware ottimizzato: Sono state scelte configurazioni basate su processori AMD EPYC ad alta frequenza. Il cluster era composto da 6 server dedicati - 3 nodi master e 3 nodi worker. Ciò ha garantito un equilibrio ottimale tra costi e prestazioni per un ambiente ad alto carico con attività di transcodifica ad alta intensità di CPU.
Alta disponibilità: La tolleranza ai guasti è stata ottenuta attraverso una configurazione di rete a più livelli. Keepalived, HaProxy e MetalLB sono stati utilizzati per eliminare i singoli punti di guasto, garantendo il funzionamento continuo del cluster e il bilanciamento del carico.
Storage distribuito: Lo storage distribuito Longhorn con replica è stato implementato per proteggere i file video critici e i dati delle applicazioni. Questa soluzione ha ridotto l'overhead associato alla replica dei dati e ha garantito la sicurezza dalla perdita dei dati, anche in caso di guasto di un nodo.
INTROSERV ha quindi fornito al cliente una piattaforma che ha eliminato il livello di virtualizzazione sui nodi worker, dando ai pod l'accesso diretto all'hardware e implementando una topologia fault-tolerant in conformità con le best practice del settore.
Kubernetes su metallo nudo: Massime prestazioni senza compromessi
Grazie al livello di competenza e all'adattabilità del team INTROSERV, il deployment del cluster Kubernetes è stato portato a termine con successo, nonostante le complessità specifiche di tale soluzione.
Il passaggio ai server dedicati INTROSERV ha permesso al team di sviluppo dell'applicazione multimediale di ottenere le massime prestazioni, irraggiungibili in ambiente cloud, e di ottenere il pieno controllo sulla propria infrastruttura.
-
Il pieno utilizzo della CPU è stato ottenuto grazie all'accesso diretto alle risorse di calcolo. L'applicazione di transcodifica è stata in grado di utilizzare tutti i 32 thread dei processori AMD EPYC su ciascun nodo worker senza l'overhead della virtualizzazione. Il tempo di elaborazione per le tipiche attività di transcodifica è stato ridotto di 4-5 volte rispetto all'ambiente cloud.
-
I singoli punti di guasto sono stati eliminati a livello di host e la protezione affidabile dei file video e dei dati delle applicazioni è stata garantita grazie allo storage distribuito Longhorn con tripla replica.
-
Il cliente è passato da bollette imprevedibili per il cloud a un canone di locazione fisso e ottimizzato per i server fisici.
Per scegliere l'infrastruttura ottimale per il vostro progetto, contattate il reparto vendite di INTROSERV.
































































