

In an era where every hour of downtime translates to missed project deadlines, and video processing speed directly impacts product competitiveness, media application developers cannot rely on architectures burdened by cloud virtualization overhead, which results in unpredictable performance and limitations in CPU utilization.
A development team from Germany requested the configuration of a K8s cluster on dedicated servers for their video transcoding application, as this solution alone ensures the full utilization of compute resources with maximum I/O values.

Goals
-
Performance: Achieve maximum I/O speed and full CPU utilization through direct hardware access, eliminating the virtualization overhead that is critical for CPU-intensive transcoding tasks.
-
High Availability: Eliminate all single points of failure at both the control plane and worker node levels, ensuring continuous cluster operation. The goal was to ensure that achieving maximum I/O and CPU performance did not compromise fault tolerance.
-
Replicated Storage: Implement distributed persistent storage with replication to safeguard critical video files and application data.
-
Cost Predictability: Replace unpredictable cloud bills with a fixed, optimized lease payment for dedicated servers.
Results
-
Full CPU Utilization: By bypassing the virtualization layer on the worker nodes, the developer provided its application with direct access to compute resources for maximum transcoding performance.
-
Fault Tolerance: Through intelligent resource and system component distribution, single points of failure were eliminated down to the host level.
-
Distributed Storage: The implementation of Longhorn reduced the overhead associated with data replication and protected against the loss of video files or the database even if any node failed.
-
Transparency and Cost Predictability: For the developer team, which provides support services for their product, the process of determining the cost of work and infrastructure maintenance expenses was simplified.
The context
The developer was working on deploying a software suite for video transcoding with exceptional platform performance requirements. After several tests on a conventional cloud platform, the client's DevOps engineers encountered a set of limitations that hindered project implementation.
The critical slowdown of the transcoding application's workloads and the client's CD/CI processes was caused by fundamental limitations of the cloud platform.
Low I/O Performance and the "Hypervisor Tax": The cloud environment prevented the pods from using the full speed of the NVMe drives for handling large video files. The actual I/O performance was artificially constrained by cloud limits and the overhead of the virtualization layer. This layer contributed to unacceptable latency during the upload of source video and the download of processed content. Furthermore, the client lacked sufficient compute resources for parallel transcoding due to two factors: a portion of CPU performance was lost to virtualization, and, apparently, due to underperforming CPUs on the cloud provider’s compute nodes.
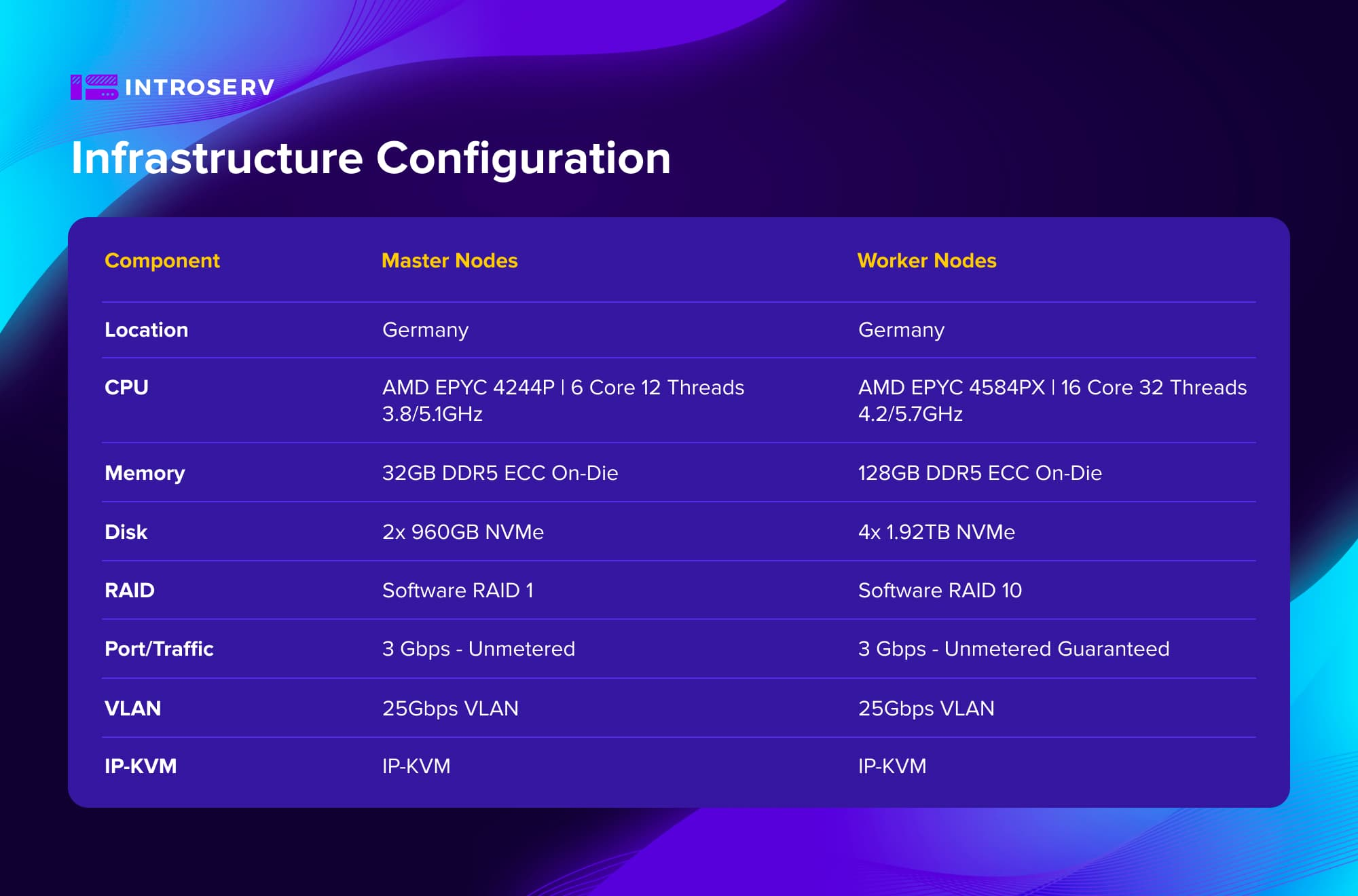
Infrastructure Configuration
The challenge
To realize the project, the following challenges needed to be addressed to ensure full customization, control, and maximum performance:
Select optimal hardware, considering the high requirements for drive speed for video files and overall cluster performance for CPU-intensive transcoding tasks.
Configure the network with high-availability requirements in mind to eliminate single points of failure at the control plane and worker levels.
Deploy a production-ready Kubernetes cluster on dedicated servers, incorporating best practices and implementing distributed persistent storage with replication to protect critical video files and application data.
The solution
In response to the request for a platform with maximum I/O metrics and compute power for the video transcoding application, the INTROSERV team deployed a high-performance Kubernetes cluster on dedicated servers.
Key Solution Components:
Optimized Hardware: Configurations based on high-frequency AMD EPYC processors were selected. The cluster consisted of 6 dedicated servers – 3 master nodes and 3 worker nodes. This ensured an optimal balance between cost and performance for a high-load environment with CPU-intensive transcoding tasks.
High Availability: Fault tolerance was achieved through a multi-layered network configuration. Keepalived, HaProxy, and MetalLB were utilized to eliminate single points of failure, guaranteeing continuous cluster operation and load balancing.
Distributed Storage: Longhorn distributed storage with replication was implemented to protect critical video files and application data. This solution reduced the overhead associated with data replication and provided safety from data loss, even in the event of any node failure.
Thus, INTROSERV provided the client with a platform that eliminated the virtualization layer on the worker nodes, giving pods direct access to the hardware, and implemented a fault-tolerant topology in accordance with industry best practices.
Kubernetes on Bare Metal: Maximum Performance Without Compromise
Thanks to the expert level and adaptability of the INTROSERV team, the deployment of the Kubernetes Cluster was completed successfully, despite the specific complexities of such a solution.
The transition to INTROSERV dedicated servers allowed the media application development team to achieve maximum performance, unattainable in the cloud environment, and gain full control over their infrastructure.
-
Full CPU utilization was achieved through direct access to compute resources. The transcoding application was able to use all 32 threads of the AMD EPYC processors on each worker node without virtualization overhead. The processing time for typical transcoding tasks was reduced by 4-5 times compared to the cloud environment.
-
Single points of failure were eliminated at the host level, and reliable protection of video files and application data was ensured thanks to Longhorn distributed storage with triple replication.
-
The client transitioned from unpredictable cloud bills to a fixed, optimized lease payment for physical servers.
To select the optimal infrastructure for your project, please contact the INTROSERV sales department.





























































